
This preprint by Jeff Rosenthal and Jinyoung Yang (currently available from Jeffs webpage) might also be called “Easily verifiable adaptive MCMC”. Jeff Rosenthal gave a tutorial on adaptive MCMC during MCMSki 2016 mentioning this work. Adaptive MCMC is based on the idea that one can use the information gathered from sampling a distribution using MCMC to improve the efficiency of the sampling process.
If two conditions, diminishing adaptation and containment are satisfied, an adaptive MCMC algorithm is valid in the sense of asymptotically consistent. Diminishing adaptation means that two consecutive Markov Kernels in the algorithm will be asymptotically equal. In other words, we either stop adaptation at some point or we know that the adaptation algorithm converges.
Containment means the number of repeated applications of all used Markov Kernels to get close to the target measure is bounded. Concretely, let 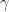






The paper is concerned with trying to find conditions for containment in adaptive MCMC that are more easily verified than those from earlier papers. First however it gives a kind of blueprint for adaptive algorithms that satisfy containment.
A blueprint for consistent adaptive MCMC
Nameley, let 


Start the algorithm at some 

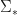
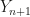
(1)
(2)


Reject if 
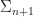
It would seem to me that we can actually change the distribution in (2) arbitrarily if we continue to meet diminishing adaptation. So for example we could use an independent metropolis, adaptive Langevin or other sophisticated proposal inside K, so long as condition (e) in the paper is satisfied, i.e. the adaptive proposal distribution used in (2) is continuous in 
General conditions for containment in adaptive MCMC
Let 

(a) The probability to move more than some finite distance D > 0 is zero:
(b) Outside of K, the algorithm uses a fixed transition kernel P that never changes (and still respects that we can at most move D far away)
(c) The fixed kernel P is bounded above by 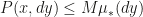



(d) The fixed kernel P is bounded below by 


(e) Let 

Here, conditions (a) and (b) are very easy to ensure even when not an expert on MCMC. Conditions (c) and (d) sound harder, but as mentioned above it seems to me that they are easy to ensure by just using a (truncated, i.e. respecting (a)) gaussian random walk proposal outside of K. Finally, (e) seems to boil down to making the adaptive proposal continuous in both
The proofs use a generalization of piecewise continuous functions and a generalized version of Dinis theorem to prove convergence in total variation distance.
This paper seems to me to be a long way from Roberts & Rosenthal (2007, Journal of Applied Probability) which was the first paper I read on ergodicity conditions for adaptive MCMC. It truly makes checking containment much easier. My one concern is that the exposition could be clearer for people that are not MCMC researchers. Then again, this is a contribution paper rather than a tutorial.


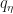 to the target density
to the target density 
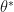 under the target when using Metropolis Hastings is
under the target when using Metropolis Hastings is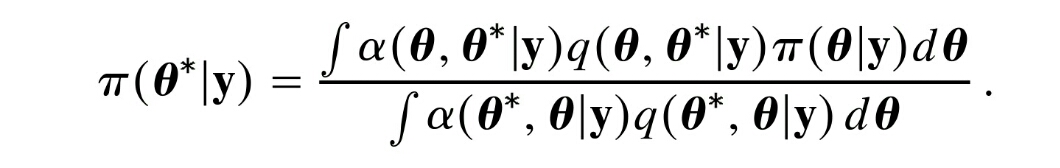
 is the proposal density,
is the proposal density,  the acceptance probability and
the acceptance probability and 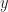 the data. If
the data. If  is the unnormalized target, we can get the evidence estimate
is the unnormalized target, we can get the evidence estimate  .
. for each sample
for each sample 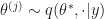 is the opposite of cheap! It involves evaluating
is the opposite of cheap! It involves evaluating 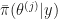 for all j, which is basically the same cost as getting samples from the target in the first place.
for all j, which is basically the same cost as getting samples from the target in the first place.
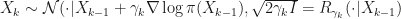
 is a Markov kernel that admits a unique stationary distribution
is a Markov kernel that admits a unique stationary distribution  that is close to the desired
that is close to the desired  decreases.
decreases. , the authors provide bounds that explicitly depend on dimensionality of the support of the target, the number of samples drawn and the chosen step size
, the authors provide bounds that explicitly depend on dimensionality of the support of the target, the number of samples drawn and the chosen step size  . Unfortunately, these bounds contain some unknowns as well, such as the Lipschitz constant
. Unfortunately, these bounds contain some unknowns as well, such as the Lipschitz constant  of the gradient of the logpdf
of the gradient of the logpdf  and some suprema that I am unsure how to get explicitly.
and some suprema that I am unsure how to get explicitly. . But hopefully with Alains paper as a foundation that can be the next step. As a non-mathematician, I had some problems in following the paper and at some point I completely lost it. This surely is in part due to the quite involved content. However, one might still manage to give intuition even in this case, as Sam Livingstones recent
. But hopefully with Alains paper as a foundation that can be the next step. As a non-mathematician, I had some problems in following the paper and at some point I completely lost it. This surely is in part due to the quite involved content. However, one might still manage to give intuition even in this case, as Sam Livingstones recent  and led to Nirvana. If not the estimation is the problem but the actual gradient, of course you have the same effect. The second assumption is also very intuitive: if the gradient leads into the tails, then it hurts rather than helps convergence. And your posterior is improper. The final assumption basically requires that your chance to improve by proposing a point closer to the origin goes to
and led to Nirvana. If not the estimation is the problem but the actual gradient, of course you have the same effect. The second assumption is also very intuitive: if the gradient leads into the tails, then it hurts rather than helps convergence. And your posterior is improper. The final assumption basically requires that your chance to improve by proposing a point closer to the origin goes to  the further you move away from it.
the further you move away from it.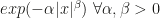 , whenever the tails of the distribution are no heavier than Laplace (
, whenever the tails of the distribution are no heavier than Laplace ( ) and no thinner than Gaussian (
) and no thinner than Gaussian ( ), HMC will be geometrically ergodic. In all other cases, it won’t.
), HMC will be geometrically ergodic. In all other cases, it won’t. , eq. (13):
, eq. (13):
 is invertible and thus a Jacobian exists to account for the transformation of
is invertible and thus a Jacobian exists to account for the transformation of  hidden in the
hidden in the  . A quick check with
. A quick check with  where
where  is the old momentum, and we mix it with another Gaussian RV of the same distribution
is the old momentum, and we mix it with another Gaussian RV of the same distribution  for some parameter
for some parameter  . We recover HMC for
. We recover HMC for  , as in that case the momentum is always refreshed.
, as in that case the momentum is always refreshed.

 of the Markov Chain, the final MH proposal
of the Markov Chain, the final MH proposal  is constructed using an intermediate step
is constructed using an intermediate step  , where the intermediate step is encouraged to have lower density than
, where the intermediate step is encouraged to have lower density than 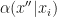 involves computing an intractable integral, as one has to integrate away the intermediate downhill move. They get around this by introducing an auxiliary variable, a technique inspired by Møller et al. (2006), where it was used to get around the computation of normalizing constants. I discussed a similar idea shortly with Jeff Miller (
involves computing an intractable integral, as one has to integrate away the intermediate downhill move. They get around this by introducing an auxiliary variable, a technique inspired by Møller et al. (2006), where it was used to get around the computation of normalizing constants. I discussed a similar idea shortly with Jeff Miller (
 . The weights of the samples drawn from these are Rao-Blackwellized using the deterministic mixture idea of Zhou and Owen, and as far as I can see only the Importance Samples are used for estimating integrands.
. The weights of the samples drawn from these are Rao-Blackwellized using the deterministic mixture idea of Zhou and Owen, and as far as I can see only the Importance Samples are used for estimating integrands.

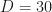 dimensions.
dimensions. The histogram has a peak at about
The histogram has a peak at about  , which means most of the samples are in a sphere around the mean/mode/MAP of the target distribution and none are at the MAP, which would correspond to norm
, which means most of the samples are in a sphere around the mean/mode/MAP of the target distribution and none are at the MAP, which would correspond to norm  .
. dimensions,
dimensions,  , computing the euclidean norm you get
, computing the euclidean norm you get  . But as
. But as  has a
has a  distribution, which results in the expected value
distribution, which results in the expected value  . Voici l’explication.
. Voici l’explication.
{kind=link}
{kind=link}