
Christian put my nose on this preprint by Tak, Meng and van Dyk a few days ago, so during the flight from Berlin to Paris today I sniffed on it. It was a very interesting read and good to get my thoughts away from the fact that I was an Opfer of German friendliness at airport security.
The basic idea is to design a random walk MH algorithm for targets with multiple and distant modes. The distant is important here, because for very close modes simple Adaptive Metropolis (Haario et al. 2001), which is simply using a scaled version of the targets covariance in a Gaussian random walk, should work pretty well.

Which it probably does not for the targets above, as such a proposal would often end up in areas of low posterior density.
Now the idea is the following: given current state 
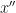

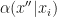
Am main argument for their algorithm is that it only needs tuning of a single scale parameter, whereas other MCMC techniques for multimodal targets are notoriously hard to tune.
In evaluation they compare to tempered transitions and equi-energy samplers and perform better both with respect to computing time and MSE. And of course human time invested in tuning.
However, I’m slightly tempted to repeat Nicolas mantra here “just use SMC”. Or slightly change the mantra to “… PMC” – because this is easier to stomach for MCMC-biased researchers, or so I believe. Of course this adds the number of particles to tuning, but that might be tuned automatically using the recent paper of the Spanish IS-connection.

{kind=link}