
This letter to Nature (also on arXiv) by Havlicek and coauthors deals with gaining a quantum computing advantage for classification problems and is written by quantum physicists. The main reason a friend brought this to my attention is that the classification problem is solved using support vector machines, thus fitting my recent interest in reproducing kernel Hilbert space (RKHS) methods.
The main idea is that the way numerical data is encoded into a quantum state can result in a nonlinear feature map into the very high dimensional quantum Hilbert space. Consecutive computation in the quantum Hilbert space then induces nonlinear methods in the input space. In this case nonlinear classification.
The main contributions over papers that are easier to read coming from an RKHS background (such as Quantum machine learning in feature Hilbert spaces by Schuld et al) are twofold. For one, Havlicek and coauthors use a feature map that does not result in a trivial/useless RKHS. Specifically they propose to use two layers of a diagonal gate and a Hadamard gate and conjecture that this gives a quantum advantage (while a single layer can be simulated classically). I am quite lost here of course without any background in quantum computing. Second, their classification algorithm was implemented and run on an actual quantum computer, rather than simulated on standard computers. In particular, they use five superconducting transmons, which seems to be a type of qubit implementation and allows for quantum coupling.
The classification problem they tackle is a toy problem that they construct so as to be perfectly separable with their classification algorithm, which is of course a good sanity check for this first step of developing actual quantum machine learning. The decision of the algorithm for any of the two classes however cannot be read from the computing device deterministically, but only stochastically. The solution, seemingly common in quantum computing, is to read out the class repeatedly to obtain samples and compute their empirical average.
The training then consists of optimizing a bias variable and a parameter 
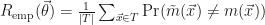
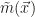
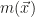

They use two main approaches, one working directly in the space spanned by the 

Personally, I would think that the variational approach makes much more sense in the mid to long term, as the canonical approach does not yield a more powerful method but induces large memory cost for large datasets. Then on the other hand I’m completely lost when thinking about how to invert a matrix in the quantum feature space or compute solutions of systems of linear equations.
Overall, I think that this is a very interesting path to follow and am keen on finding out how quantum computing and machine learning/statistics might combine in beneficial ways.

 .
.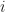 th eigenvalue of the covariance operator (and shared by the kernel matrix) as
th eigenvalue of the covariance operator (and shared by the kernel matrix) as  , where
, where 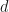 is the dimension of the problem,
is the dimension of the problem,  are constants and
are constants and  is a constant depending on the kernel and the domain.
is a constant depending on the kernel and the domain.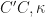 and
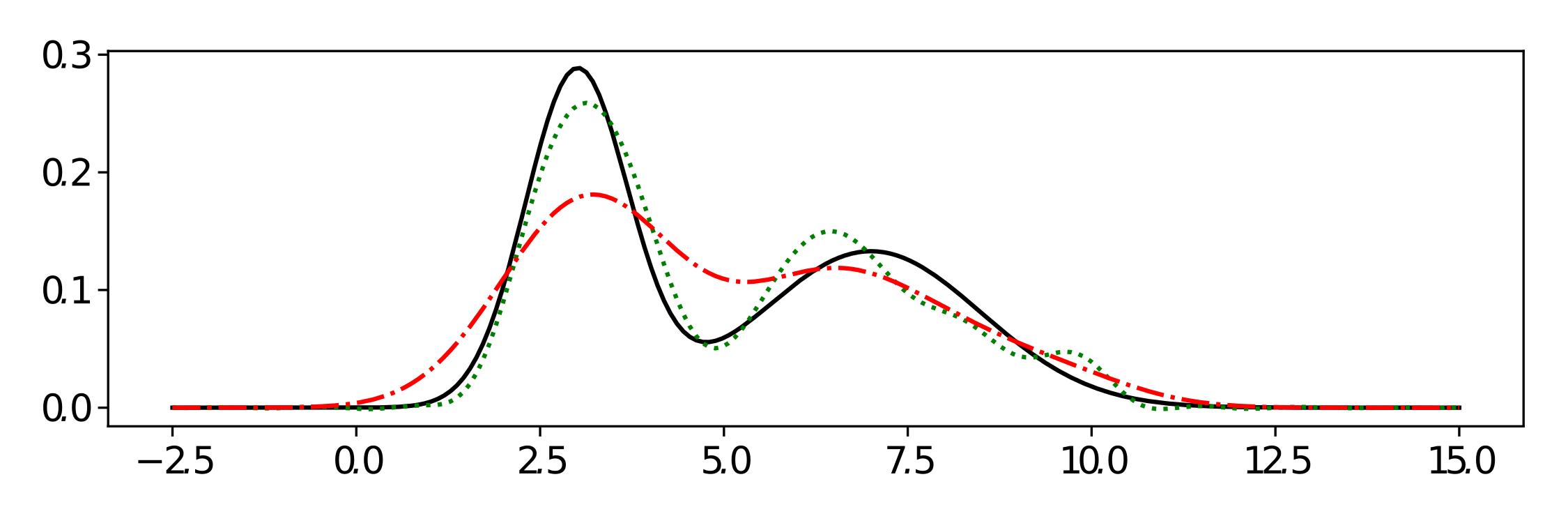
and 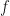 can be approximated very well by the first few eigenfunctions, or in other words
can be approximated very well by the first few eigenfunctions, or in other words 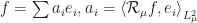 where
where 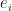 are the eigenfunctions, satisfies the decay condition
are the eigenfunctions, satisfies the decay condition 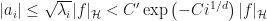 . Which sounds like spectacular news, actually.
. Which sounds like spectacular news, actually. be the KME/KDE functional for a density
be the KME/KDE functional for a density  (with respect to reference measure
(with respect to reference measure  ) of distribution
) of distribution 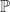 , and assume that this density is in the RKHS. Then
, and assume that this density is in the RKHS. Then 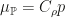 , where
, where 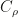 is the covariance operator with respect to the reference measure. Thus we can recover
is the covariance operator with respect to the reference measure. Thus we can recover 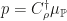 .
. .
.


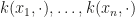 contains the interpolating solution that has minimum RKHS norm. As existing generalization bounds depend on this norm, it’s obvious that this inductive bias is advantageous.
contains the interpolating solution that has minimum RKHS norm. As existing generalization bounds depend on this norm, it’s obvious that this inductive bias is advantageous. 
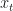 capturing the systems state (i.e. the observed state in HMM lingo or observables in dynamical systems lingo), the control input
capturing the systems state (i.e. the observed state in HMM lingo or observables in dynamical systems lingo), the control input  and the observed state at the following time index
and the observed state at the following time index 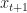 .
.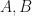 satisfying
satisfying ![[x_{t+1}, u_{t+1}] = [A,B] [x_{t}^\top, u_t^\top]^\top](https://s0.wp.com/latex.php?latex=%5Bx_%7Bt%2B1%7D%2C%C2%A0u_%7Bt%2B1%7D%5D+%3D+%5BA%2CB%5D+%5Bx_%7Bt%7D%5E%5Ctop%2C+u_t%5E%5Ctop%5D%5E%5Ctop&bg=ffffff&fg=141412&s=0&c=20201002) , where
, where 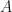 encodes the dependence of the next state upon the current state,
encodes the dependence of the next state upon the current state,  upon the control. Already, this formula reveals a slight inelegance – to stay in Koopman operator world, the control input at
upon the control. Already, this formula reveals a slight inelegance – to stay in Koopman operator world, the control input at  is predicted. This does not make much sense, but so be it.
is predicted. This does not make much sense, but so be it. and
and  , where
, where  is some nonlinear map to
is some nonlinear map to 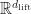 and called a lifting function in the paper. Now to fit a model to the nonlinear system dynamics, we only need to fit the linear maps
and called a lifting function in the paper. Now to fit a model to the nonlinear system dynamics, we only need to fit the linear maps ![\min_{A,B} | [\phi(x_{2}), \dots, \phi(x_{T})] - A [\phi(x_{1}), \dots, \phi(x_{T-1})] - B[u_{1}, \dots, u_{T-1}] \|](https://s0.wp.com/latex.php?latex=%5Cmin_%7BA%2CB%7D+%7C+%5B%5Cphi%28x_%7B2%7D%29%2C+%5Cdots%2C%C2%A0%5Cphi%28x_%7BT%7D%29%5D+-+A%C2%A0%5B%5Cphi%28x_%7B1%7D%29%2C+%5Cdots%2C%C2%A0%5Cphi%28x_%7BT-1%7D%29%5D+-+B%5Bu_%7B1%7D%2C+%5Cdots%2C%C2%A0u_%7BT-1%7D%5D+%5C%7C&bg=ffffff&fg=141412&s=0&c=20201002)
![[A, B] = [\phi(x_{2}), \dots, \phi(x_{T})] [\phi(x_{1}), \dots, \phi(x_{T-1}),u_{1}, \dots, u_{T-1}]^{-1}](https://s0.wp.com/latex.php?latex=%5BA%2C+B%5D+%3D+%5B%5Cphi%28x_%7B2%7D%29%2C+%5Cdots%2C%C2%A0%5Cphi%28x_%7BT%7D%29%5D+%5B%5Cphi%28x_%7B1%7D%29%2C+%5Cdots%2C%C2%A0%5Cphi%28x_%7BT-1%7D%29%2Cu_%7B1%7D%2C+%5Cdots%2C%C2%A0u_%7BT-1%7D%5D%5E%7B-1%7D&bg=ffffff&fg=141412&s=0&c=20201002)
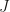 that includes both the cost of the system deviating from the target state as well as the cost of control inputs. As the cost is convex, a global optimum can be attained.
that includes both the cost of the system deviating from the target state as well as the cost of control inputs. As the cost is convex, a global optimum can be attained.




