
This arXival by the dynamical duo Korda & Mesiç deals with optimal control for a dynamical system when no forward differential equations are known. Instead, we are given observation/sensor data 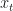

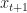
The basic idea is to build a Koopman operator that captures the dynamics of the observed data. In the simplest case, this operator is just a linear map, i.e. matrices 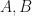
![[x_{t+1}, u_{t+1}] = [A,B] [x_{t}^\top, u_t^\top]^\top](https://s0.wp.com/latex.php?latex=%5Bx_%7Bt%2B1%7D%2C%C2%A0u_%7Bt%2B1%7D%5D+%3D+%5BA%2CB%5D+%5Bx_%7Bt%7D%5E%5Ctop%2C+u_t%5E%5Ctop%5D%5E%5Ctop&bg=ffffff&fg=141412&s=0&c=20201002)
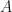


Now the trick to approximate nonlinear dynamics is well known to statisticians and ML people: rather finding a mapping between 


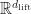
![\min_{A,B} | [\phi(x_{2}), \dots, \phi(x_{T})] - A [\phi(x_{1}), \dots, \phi(x_{T-1})] - B[u_{1}, \dots, u_{T-1}] \|](https://s0.wp.com/latex.php?latex=%5Cmin_%7BA%2CB%7D+%7C+%5B%5Cphi%28x_%7B2%7D%29%2C+%5Cdots%2C%C2%A0%5Cphi%28x_%7BT%7D%29%5D+-+A%C2%A0%5B%5Cphi%28x_%7B1%7D%29%2C+%5Cdots%2C%C2%A0%5Cphi%28x_%7BT-1%7D%29%5D+-+B%5Bu_%7B1%7D%2C+%5Cdots%2C%C2%A0u_%7BT-1%7D%5D+%5C%7C&bg=ffffff&fg=141412&s=0&c=20201002)
For the Frobenius norm, the analytical solution is
![[A, B] = [\phi(x_{2}), \dots, \phi(x_{T})] [\phi(x_{1}), \dots, \phi(x_{T-1}),u_{1}, \dots, u_{T-1}]^{-1}](https://s0.wp.com/latex.php?latex=%5BA%2C+B%5D+%3D+%5B%5Cphi%28x_%7B2%7D%29%2C+%5Cdots%2C%C2%A0%5Cphi%28x_%7BT%7D%29%5D+%5B%5Cphi%28x_%7B1%7D%29%2C+%5Cdots%2C%C2%A0%5Cphi%28x_%7BT-1%7D%29%2Cu_%7B1%7D%2C+%5Cdots%2C%C2%A0u_%7BT-1%7D%5D%5E%7B-1%7D&bg=ffffff&fg=141412&s=0&c=20201002)
where the inverse is the pseudoinverse of course. Up to here, the paper was all about approximating a forward model from data in the case where no a priori closed form DE model is given.
Now the idea for using this for control is to define a convex cost function 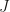
The theoretical analysis mainly shows that the approximated Koopman operator converges to the actual infinite dimensional Koopman operator.
While the extension to stochastic systems is only mentioned, I think this is an interesting paper following an approach that seems particularly promising for whats called reinforcement learning in the deep/machine learning community. It seems that many reinforcement learning papers do not use a proper optimisation procedure for control input (it’s just random search). Fitting a model of the systems dynamics and its reaction to control input instead, enabling the usage of well-known gradient based optimisation methods, as the current paper, seems like a good idea to me.
