
This is a most interesting ICML paper by Belkin, Ma and Mandal. Its starting point (as in seemingly many recent papers by Belkin) is the observation that there is robust generalisation performance of statistical models for interpolating solutions/solutions with zero training error, an observation previously made by Recht and Bengio for deep learning. The authors find that this phenomenon persists if we change the model class from deep networks to kernel machines. In particular, the non-smooth Laplacian kernel can fit random training labels in a classification problem.
On the other hand, the authors provide bounds for smooth kernels that diverge with increasing data. To arrive at this conclusion they show that the norm of interpolating solutions diverges with the number of data points (they call interpolating solutions “overfitted” which I think is not the best term). This implies divergence of generalisation bounds as well, as they depend on the norm of the solution.
The assumption needed for the theoretical results is that the label noise of the training data is nonzero. Experimentally, the paper checks how interpolating kernel classifiers perform in this case using synthetic datasets with known label noise and real world data sets with added noise. Here, the empirical test performance of the interpolating kernel classifier is slightly below the noise level, showing near optimal performance. This parallels the performance of deep networks.
The paper concludes that a deep architecture, as such, is not responsible for the good test performance of zero-training-error solutions. And as almost all bounds for RKHS methods depend on the norm of the solution, that a new theory is needed for these zero-training-error regimes. A complementary finding is that optimisation for fitting random labels is more demanding with Gaussian kernels as compared to non-smooth Laplacian kernels.
The authors conjecture that inductive bias, rather than regularisation, is particularly important in deep learning and kernel methods. Concretely, for kernel methods, the span of the canonical features at the data points 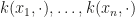
I agree with the authors in that (frequentist) kernel methods are a good place to start analysing minimum norm solutions, as here they are often available in closed form, unlike in (frequentist) deep learning.
