We recently submitted and arXived our new work on (conditional) density reconstruction methods using the reproducing kernel Hilbert space (RKHS) formalism. This is work with relentless PhD candidate Mattes Mollenhauer, Stefan Klus and Krikamol Muandet. It seeks to provide theory for an idea that came up over the course of working on eigendecompositions of RKHS operators and was catalysed by a characterization of the kernel mean embedding (KME) object, aka the classical kernel density estimate (KDE)/Parzen window estimate, that Stefan derived in another paper.
The key insight that we started out with is the follwing. Let 


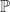
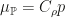
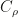
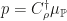
This is stated in Fukumizus Kernel Bayes rule paper for the general case of Radon-Nikodym derivatives, and later on in our work, though we didn’t realize the connections at first. So to be more precise: if the reference measure is Lebesgue, we estimate densities in the usual sense. In general Radon-Nikodym derivatives are estimated, i.e. 
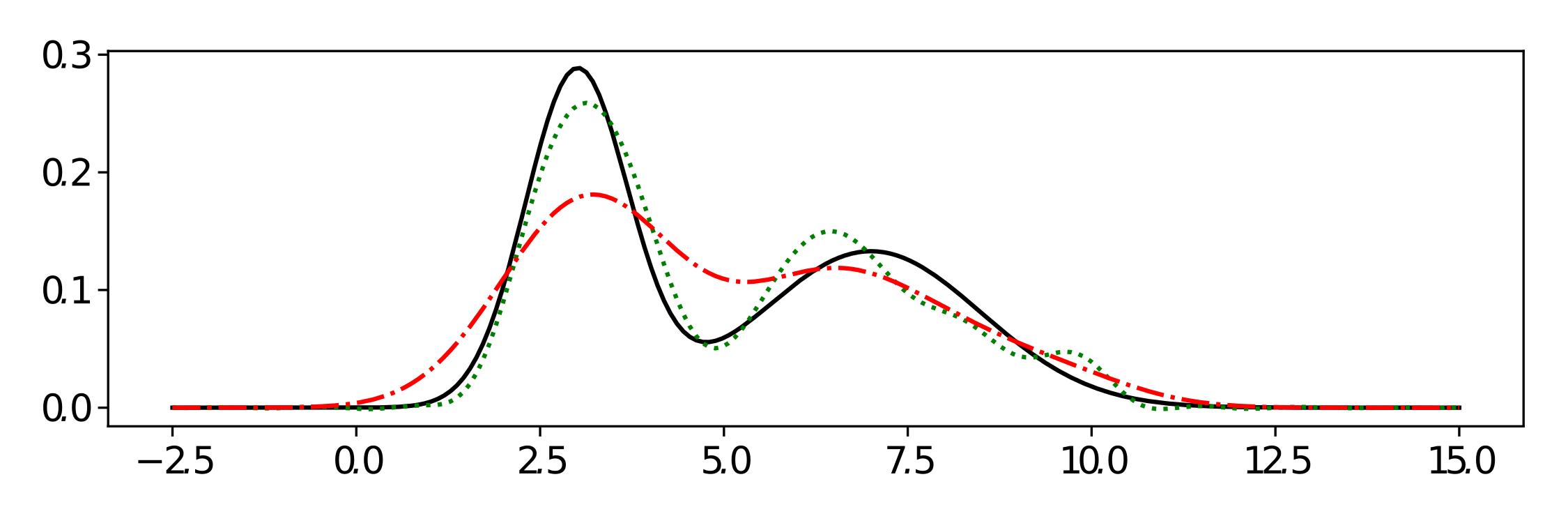
Ground truth in black.
A first impression of the resulting estimates is given above. When choosing Lebesgue measure as the reference, we can estimate the density in the usual sense as given by the green curve using 200 samples from the true black density. Using a Tikhonov approach, we prove dimensionality-independent bounds on the stochastic error of this reconstruction depending mostly on the norm of the KME/KDE function and the number of samples.
The real power of this idea however is conditional density estimation. While there already is the vernerable Gaussian process (GP) as a kernel-based method in this field, our method yields many advantages. Among them are of-the shelve modelling of arbitrary output dimensions and multiple modes, whereas standard GPs can only handle one dimension and mode. In the example below, this is demonstrated in a toy example based on a ring with gaussian noise in 3d. Both capabilities are demonstrated, multimodal and multidimensional output that easily captures correlations between the dimensions.

And as no paper would be complete without deep learning, we compare the resulting conditional density operator (CDO) to a neural network based conditional density model using RealNVP. Finding the CDO outperforms the RealNVP by orders of magnitude, although the latter was tuned for quite some time by colleagues at Zalando Research for the dataset used.
Fingers crossed for the review process and thanks to my wonderful coauthors.
