
This paper by Mikhail Belkin from COLT 2018 (arXiv) takes a hard look at the main source of error for statistical problems solved using RKHS methodology. Unsurprisingly finding that approximation-theoretical results provide much sharper error bounds than the typical statistical concentration results with rate 
For a class of radial kernels, the paper shows nealy exponential decay of covariance operator eigenvalues and of function coordinates with respect to the eigenbasis. The radial kernel class is characterized by rather obscure (to me) conditions, but includes Gaussian, inverse multiquadric and Cauchy kernels. Notably, Belkin doesn’t mention Laplace kernels here, which seem to be his favorite. His main result, in my mind, is contained in theorem 2 and bounds the 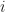

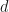


The implications of this are many. First, the number of samples needs to be nearly exponantial in the eigenvalue index for concentration bounds to be sharper than these approximation theory based bounds. Second, approximation theory bounds need no iid assumptions on the samples. Third, they are, according to the author, independent of the reference measure of the L2-space, which is at the same time the measure used for the covariance operator. While the latter is true in principle, I want to hint at the fact that the null sets of the reference measure is the only thing that does matter, as it influences the span of the eigenbasis.
For Kernel conditional density operators, the nearly exponetial eigenvalue decay contains a mixed message. Good news is that we now know better what to expect for the conditioning of the non-stochastic inverse problem. But slow eigenvalue decay would be good, which we definitely do not have for the class of kernels Belkin considers. The hope then is that one can get a handle on the constants in the bound, 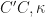
On the other hand, Theorem 3 shows that a function 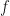
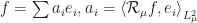
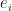
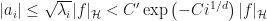
Overall the paper is a very interesting read and very enlightening. Obviously, I am still undecided of what the results actually mean for some kernel methods.
