
Category Archives: Uncategorized

Optimization Monte Carlo
A very short note on Optimization Monte Carlo by Meeds and Welling. Max Welling gave a talk on this at a NIPS workshop, during which unfortunately I wasn’t very attentive. Unfortunately because they propose essentially the same thing as David Duvenaud and coauthors did in Early stopping is nonparametric variational inference, which I was super-vocal in criticizing just 2h earlier at Davids poster. Now because I didn’t closely listen at Max’ talk and because it was Max Welling rather than David, I wasn’t all so vocal, but took the discussion with Max offline.
(The following critique is not actually valid for this paper, read the edit)
The critique is essentially the same: if you draw an RV and then optimize it, you can’t compute the Jacobian to correct for the transformation, because the transformation is typically not bijective (think gradient ascent: let 
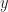


I’ll stop here, as I asked Xi’an for his opinion and he will post about this as well, presumably with a more detailed discussion. If Ted Meeds and Max Welling answer to my email on this and prove me wrong, I’ll update this post of course.
EDIT 1: Lesson learned. I shouldn’t post with only half understanding the paper (if half is not said too much). They don’t actually suggest optimizing an RV and computing the Jacobian of the transformation. Rather, they propose optimizing another variable, which is not taken to be random (the parameters of a simulator, which is specific to the ABC setting).
EDIT 2: Xi’ans post
A Complete Recipe for Stochastic Gradient MCMC
Another NIPS paper, this one by Ma, Chen and Fox. This one is interesting in that it seeks to build a framework for MCMC algorithms which only use random subsamples of the data. This is achieved by considering the general form of continuous Markov processes as an SDE given by

where 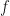

They use this to show ways of reconstructing known stochastic sampling algorithms and give a new sampler, which is a stochastic version of Riemannian HMC.
The paper is very honest in stating the limitations of SG sampling, namely that one has to diminish the learning rate to infinitesimal values (i.e. 0) to ensure unbiasedness. Which would defeat the purpose of sampling of course.
The Sample Size Required in Importance Sampling

A very exiting new preprint by Chatterjee and Diaconis takes a new look at the old Importance Sampling. While its masks as a constructive paper (maybe because of publication bias), its main result to me is actually the deconstruction of an IS myth. Let me elaborate.
The paper shows that the variance estimate for an Importance Sampling estimator is not a good diagnostic for convergence. An implication of this is that aiming for low variance of importance weights, or equivalently high Effective Sample Size, might be better then nothing, but is not actually that great. In more mathy speak, high ESS is a necessary condition for convergence of the estimate, but not a sufficient condition.
Especially in your face is their result that for any 


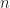
However, they propose a new convergence diagnostic which is basically plagued by a similar problem. They even state themselves that their alternative criterion 
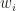
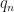
Computing Functions of Random Variables via Reproducing Kernel Hilbert Space Representations
This paper by Schölkopf et al in Statistics and Computing (and on arXiv, which I will refer to when giving page numbers) was a very rewarding read. Although I think the promise of “Kernel Probabilistic Programming” given in the abstract is not really kept, it served me as a concise review of ideas in modern (i.e. distribution based) methods using positive definite kernels. The obvious connection of the pd kernel mean map with kernel density estimators is just one of the things that I think are important to realize in this domain.
Estimating integrals of functions in a certain RKHS becomes a rather straight forward exercise in the proposed framework. However, it’s a bit unfortunate that they assume independent samples from the distribution, but posing this as an IS estimator one might be able to apply some elementary results leading to a generalization for dependent samples (they talk about application to dependent samples, but I felt that was geared only towards causal inference). What might get in the way here is that their estimators are assumed to be independent of the actual samples used (which is not the case in IS).
These difficulties with their estimator for functions of RVs notwithstanding, what struck me again and again is the close connection with importance sampling estimators (I’m a one trick pony). Specifically, the used empirical kernel mean map of a set of samples X ![\hat \mu[X] = \sum_{x \in X} \alpha(x) k(\cdot,x)](https://s0.wp.com/latex.php?latex=%5Chat+%5Cmu%5BX%5D+%3D+%5Csum_%7Bx+%5Cin+X%7D+%5Calpha%28x%29+k%28%5Ccdot%2Cx%29&bg=ffffff&fg=141412&s=0&c=20201002)



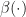
I would be really interested to see wether this IS connection is fruitful.
On a more critical note, the paper states that no parametric assumptions on the embedded distributions are made. While this is true, it masks the fact that different types of pd kernels used for the embedding will result in better or worse approximations of integrals in this framework when using finite numbers of samples. Also, the paper claims their method “does not require explicit density estimation as an intermediate step” while still using the kernel mean map, which includes KDEs as a special case. A minor thing is that Figure 1 needs error bars badly.
Frank-Wolfe Bayesian Quadrature
This paper (arXiv) on Bayesian Quadrature with actual theoretical guarantees starts from sigma point rules for approximating integrals. “Sigma point rule” is just a fancy name for using weighted samples, where weights are not constrained in any way (and will actually be negative sometimes in the algorithm).
The basic idea is to approximate the target distribution 


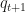
However, the nice thing in this paper is that they actually provide theoretical guarantees that their integral estimates are consistent and converge at rate 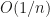

The crucial point seems to me to be the following: while the estimator has a superior rate, picking design points costs 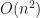


In the sense of conclusive story for the paper, I think it is a bit unfortunate that for the evaluation the paper uses iid samples directly from
I wonder wether it is mostly the idea of extrapolating
