Another NIPS paper, this one by Ma, Chen and Fox. This one is interesting in that it seeks to build a framework for MCMC algorithms which only use random subsamples of the data. This is achieved by considering the general form of continuous Markov processes as an SDE given by

where 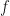

They use this to show ways of reconstructing known stochastic sampling algorithms and give a new sampler, which is a stochastic version of Riemannian HMC.
The paper is very honest in stating the limitations of SG sampling, namely that one has to diminish the learning rate to infinitesimal values (i.e. 0) to ensure unbiasedness. Which would defeat the purpose of sampling of course.
