This very remarkable NIPS paper by Mahsereci and Hennig (from my beloved Tübingen where I was an undergrad) deals with getting rid of learning rates for SGD. It does so by placing a GP prior on the value of the objective function along the search direction and its gradients projected onto the search direction. The pd kernel used for the GP is that of a once-integrated Wiener Process, resulting in a cubic spline posterior. They argue that this particular form is advantageous because its minima can be found exactly in linear time – tada! This of course is great news, because, paraphrasing the paper, you don’t want to run an optimization algorithm to find minima inside of the line search routine of the actual optimization algorithm. Another reason for choosing the particular pd kernel is that it does not assume an infinite number of derivatives of the GP (such as the Gaussian RBF does) – making it robust to irregularities in the Loss function.
Another point this rich paper makes is that the Wolfe conditions for termination of the line search procedure are actually positivity constraints. And that the probability of the constraints being satisfied can be modeled by a Gaussian CDF. If the probability is greater that 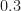
Generally speaking, the authors do a very nice job of getting rid of any free parameters in their approach, leading to a black box line search which can be used in SGD, effectively eliminating the dreaded learning rate. What I, as a sampling person, would really be interested in is whether or not this could actually be put to good use in Monte Carlo as well. However, it is delicate to use gradient information in sampling and not introduce bias, so I think this might be very difficult.
