Update: This paper has been accepted to AISTATS. As far as I can see, in exactly the same version that I review here.
This preprint by Maclaurin, Duvenaud and Adams suggested to be a very interesting read. Their idea is that stochastic optimization of a Bayesian Model could be seen as sampling from a variational approximation of the target distribution. Indeed this does not seem surprising given the consistency results for Stochastic Gradient Langevin Dynamics by Teh et al. A major gist of the paper is that the variational approximation can be used to estimate a lower bound of the models marginal likelihood/model evidence. This estimate is used throughout evaluations.
However in its current version the paper exhibits several weaknesses, the least of which is the experiments, with which I will start (using the psychologically researched foot-in-the-door-technique 😉 ). In their first experiment they optimized the parameters of a neural network without regularization on the parameters. This is equivalent to using an improper prior – but this makes the marginal likelihood completely useless for Bayesian model comparison because of the Marginalization Paradox. Basically the problem is that improper priors are only known proportionally – and marginal likelihood could be anything because of that. To get an intuition for this, observe that the marginal likelihood satisfies 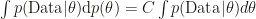 , where C is some constant that can be anything because
, where C is some constant that can be anything because 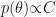 is always a correct characterization of the improper prior. In the other experiments, a statement on whether the prior is proper or improper is absent.
is always a correct characterization of the improper prior. In the other experiments, a statement on whether the prior is proper or improper is absent.
Also they claim that sampling from some distribution q and taking a stochastic gradient step computed from the partial posterior, they are able to compute the Jacobian for this step. This however is impossible because the gradient step is not bijective. Consider for example a univariate Gaussian distribution and taking a gradient step. You could end up at the mode from two values of equal log posterior density and equally large gradients pointing towards the mode. But if you can end up at the mode from two different points, then the gradient step is not injective and thus definitely not bijective. Hence no computable Jacobian transformation. I hit upon the same problem in my early ideas for Gradient Importance Sampling, which is why in that algorithm the gradient is not used for an optimization step after sampling but rather to inform the sampling distribution.
A further problem is that they seem to assume that evaluating the log posterior of only part of the data represents an unbiased estimate of the log posterior using all of the data. This is not true, in fact using minibatches can introduce small sampling bias – this being the reason that Consensus Monte Carlo introduces a Jackknife debiasing procedure and the motivation behind Heiko Strathmanns work on removing subsampling bias in MCMC for big data (another example being the paper on tall data by Remi Bardenet, Arnaud Doucet and Chris Holmes).
Finally, and I’ll end here, they state that a limitation of their method might be that
using only a single sample to estimate both the expected likelihood as well as the entropy of an entire distribution will necessarily have high variance under some circumstances
This is understating things – I’m not sure a single sample will have finite variance at all.
I really hope that they can improve on this work, but it won’t be a piece of cake.
EDIT: I talked to David Duvenaud at his poster at a NIPS workshop today. While I still think my objections are valid, I was harsher than I wished I had been (I wanted to be constructive, but I just have no idea how one could proceed and ended up just criticizing, which must have been very frustrating). Just to clarify: even when you do not end up at the mode after a gradient step, the step still is not invertible, resulting in it being not bijective.
 With my son, my niece, sister and her boyfriend I visited the science museum in Mannheim about two months ago. There where many nice experiments, and as a (former ?) computer scientist I was particularly impressed by Leibniz’ mechanical digital calculator, completed in the 17th century and able to do all four basic arithmetic operations. This of course is another example for the superiority of Leibniz over Newton…
With my son, my niece, sister and her boyfriend I visited the science museum in Mannheim about two months ago. There where many nice experiments, and as a (former ?) computer scientist I was particularly impressed by Leibniz’ mechanical digital calculator, completed in the 17th century and able to do all four basic arithmetic operations. This of course is another example for the superiority of Leibniz over Newton…


 However, this of course comes at the price of higher computational complexity, similar to related methods such as Riemannian Manifold MALA/HMC. If your dataset is large however and evaluating the likelihood majorizes evaluating the Gram matrix on your particle system, this method will still have an edge over others when the support is nonlinear. For the MCMC predecessor KAMH/Kameleon see
However, this of course comes at the price of higher computational complexity, similar to related methods such as Riemannian Manifold MALA/HMC. If your dataset is large however and evaluating the likelihood majorizes evaluating the Gram matrix on your particle system, this method will still have an edge over others when the support is nonlinear. For the MCMC predecessor KAMH/Kameleon see 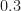 (this threshold being motivated in the paper), the algorithm is done.
(this threshold being motivated in the paper), the algorithm is done.