
During the super nice International Conference on Monte Carlo techniques in the beginning of July in Paris at Université Descartes (photo), which featured many outstanding talks, one by Tong Zhang particularly caught my interest. He talked about several variants of Stochastic Gradient Descent (SGD) that basically use variance reduction techniques from Monte Carlo algorithms in order to improve the convergence rate versus vanilla SGD. Even though some of the papers mentioned in the talk do not always point out the connection to Monte Carlo variance reduction techniques.
One of the first works in this line, Accelerating Stochastic Gradient Descent using Predictive Variance Reduction by Johnson and Zhang, suggests using control variates to lower the variance of the loss estimate. Let 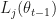

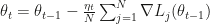

In naive SGD instead one picks a data point index uniformly 
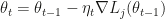
The authors choose a well-known solution to this, namely the introduction of a control variate. Keeping a version of the parameter that is close to the optimum, say 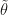

The contribution, apart from the novel combination of knowledge, is the proof that this improves convergence. This proof assumes smoothness and strong convexity of the overall loss function and convexity of the 

 With my son, my niece, sister and her boyfriend I visited the science museum in Mannheim about two months ago. There where many nice experiments, and as a (former ?) computer scientist I was particularly impressed by
With my son, my niece, sister and her boyfriend I visited the science museum in Mannheim about two months ago. There where many nice experiments, and as a (former ?) computer scientist I was particularly impressed by  ).
).
