 With my son, my niece, sister and her boyfriend I visited the science museum in Mannheim about two months ago. There where many nice experiments, and as a (former ?) computer scientist I was particularly impressed by Leibniz’ mechanical digital calculator, completed in the 17th century and able to do all four basic arithmetic operations. This of course is another example for the superiority of Leibniz over Newton…
With my son, my niece, sister and her boyfriend I visited the science museum in Mannheim about two months ago. There where many nice experiments, and as a (former ?) computer scientist I was particularly impressed by Leibniz’ mechanical digital calculator, completed in the 17th century and able to do all four basic arithmetic operations. This of course is another example for the superiority of Leibniz over Newton…
One piece was a pure exhibit with no experiments: a system of cogwheels connected sequentially, where each added wheel took ten times longer for one complete cycle compared to the one before. While the first wheel needed five seconds, the 17th and last one did not seem to move, and indeed it completes a cycle about every 1.6 billion years (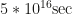
This is an example of exponential growth of course, so I told him the rice on chessboard story, e.g. the idea that starting with one grain of rice on the first square of a chessboard and doubling it on the next leads to loads and loads of rice. When he asked for rice this weekend I was rather unsuspecting, until he spilled some of it and asked for our help cleaning it up. He started the first four squares (though with linear growth as he didn’t remember completely) and we completed the first row together – after which I started simply weighing the rice, as counting took about a second per grain and already for the 256 grains on h2 I was too impatient, let alone the 1024 for f2, which would have taken about 16 minutes to count. If this little exercise doesn’t drive home what exponential growth means, I don’t know what would.

 and
and 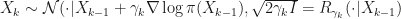
 is a Markov kernel that admits a unique stationary distribution
is a Markov kernel that admits a unique stationary distribution  that is close to the desired
that is close to the desired  decreases.
decreases. , the authors provide bounds that explicitly depend on dimensionality of the support of the target, the number of samples drawn and the chosen step size
, the authors provide bounds that explicitly depend on dimensionality of the support of the target, the number of samples drawn and the chosen step size  . Unfortunately, these bounds contain some unknowns as well, such as the Lipschitz constant
. Unfortunately, these bounds contain some unknowns as well, such as the Lipschitz constant 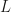 of the gradient of the logpdf
of the gradient of the logpdf  and some suprema that I am unsure how to get explicitly.
and some suprema that I am unsure how to get explicitly. . But hopefully with Alains paper as a foundation that can be the next step. As a non-mathematician, I had some problems in following the paper and at some point I completely lost it. This surely is in part due to the quite involved content. However, one might still manage to give intuition even in this case, as Sam Livingstones recent
. But hopefully with Alains paper as a foundation that can be the next step. As a non-mathematician, I had some problems in following the paper and at some point I completely lost it. This surely is in part due to the quite involved content. However, one might still manage to give intuition even in this case, as Sam Livingstones recent 
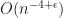 . The transformation being to replace the uniform coordinate
. The transformation being to replace the uniform coordinate  by
by  for
for  and
and  else.
else.
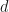 dimensional integrand which does not live on a lower dimensional manifold, and only use
dimensional integrand which does not live on a lower dimensional manifold, and only use  . Then equidistributing these
. Then equidistributing these 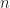 points meaningfully in becomes impossible. Of course if the integrand does live on a lower dimensional manifold, one can use that fact to get convergence rates that correspond to the dimensionality of that manifold, which corresponds (informally) to what Art Owen calls effective dimension. Two definitions of effective dimension variants are given, both using the ANOVA decomposition. ANOVA only crossed my way earlier through my wifes psychology courses in stats, where it seemed to be a test mostly, so I’ll have delve more deeply into the decomposition method. It seems that basically, the value of the integrand
points meaningfully in becomes impossible. Of course if the integrand does live on a lower dimensional manifold, one can use that fact to get convergence rates that correspond to the dimensionality of that manifold, which corresponds (informally) to what Art Owen calls effective dimension. Two definitions of effective dimension variants are given, both using the ANOVA decomposition. ANOVA only crossed my way earlier through my wifes psychology courses in stats, where it seemed to be a test mostly, so I’ll have delve more deeply into the decomposition method. It seems that basically, the value of the integrand  is treated as a dependent variable while the
is treated as a dependent variable while the 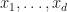 are the independent variables and ANOVA is used to get an idea of how independent variables interact in producing the dependent variable. In which case of course we would have to get some meaningful samples of points
are the independent variables and ANOVA is used to get an idea of how independent variables interact in producing the dependent variable. In which case of course we would have to get some meaningful samples of points  which currently seems to me like circling back to the beginning, since meaningful samples are what we want in the first place.
which currently seems to me like circling back to the beginning, since meaningful samples are what we want in the first place.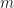 of deterministic QMC points, randomize them
of deterministic QMC points, randomize them  times using independently drawn random variables. The integral estimates
times using independently drawn random variables. The integral estimates 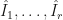 are unbiased estimates of the true integral
are unbiased estimates of the true integral 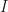 with some variance
with some variance 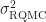 . Averaging over the $latex \hat I_i$ we get another unbiased estimator $latex \hat I$ which has variance
. Averaging over the $latex \hat I_i$ we get another unbiased estimator $latex \hat I$ which has variance 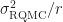 . This RQMC variance can be estimated unbiasedly as
. This RQMC variance can be estimated unbiasedly as  . If
. If  then
then  and led to Nirvana. If not the estimation is the problem but the actual gradient, of course you have the same effect. The second assumption is also very intuitive: if the gradient leads into the tails, then it hurts rather than helps convergence. And your posterior is improper. The final assumption basically requires that your chance to improve by proposing a point closer to the origin goes to
and led to Nirvana. If not the estimation is the problem but the actual gradient, of course you have the same effect. The second assumption is also very intuitive: if the gradient leads into the tails, then it hurts rather than helps convergence. And your posterior is improper. The final assumption basically requires that your chance to improve by proposing a point closer to the origin goes to  the further you move away from it.
the further you move away from it.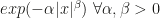 , whenever the tails of the distribution are no heavier than Laplace (
, whenever the tails of the distribution are no heavier than Laplace ( ) and no thinner than Gaussian (
) and no thinner than Gaussian ( ), HMC will be geometrically ergodic. In all other cases, it won’t.
), HMC will be geometrically ergodic. In all other cases, it won’t. , eq. (13):
, eq. (13):
 is invertible and thus a Jacobian exists to account for the transformation of
is invertible and thus a Jacobian exists to account for the transformation of 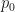 hidden in the
hidden in the  . A quick check with
. A quick check with 
