Low discrepancy (top) vs. randomly uniform points (bottom)
Mathieu Gerber gave me this 1998 paper by Art Owen as one of several references for good introductions to QMC in the course of evaluating an idea we had at MCMSki.
The paper surveys re-randomization of low discrepancy/QMC point sets mostly as a way of getting an estimate of the variance of the integral estimate. Or that is what the paper makes states most prominently – another reason for doing randomized QMC being that in some cases it further decreases variance as compared to plain QMC.
One of the things this paper stresses is that QMC will not help in truly high-dimensional integrands: say you have a dimensional integrand which does not live on a lower dimensional manifold, and only use . Then equidistributing these points meaningfully in becomes impossible. Of course if the integrand does live on a lower dimensional manifold, one can use that fact to get convergence rates that correspond to the dimensionality of that manifold, which corresponds (informally) to what Art Owen calls effective dimension. Two definitions of effective dimension variants are given, both using the ANOVA decomposition. ANOVA only crossed my way earlier through my wifes psychology courses in stats, where it seemed to be a test mostly, so I’ll have delve more deeply into the decomposition method. It seems that basically, the value of the integrand is treated as a dependent variable while the are the independent variables and ANOVA is used to get an idea of how independent variables interact in producing the dependent variable. In which case of course we would have to get some meaningful samples of points which currently seems to me like circling back to the beginning, since meaningful samples are what we want in the first place.
The idea for getting variance of the integral estimate from RQMC is the following: given a number of deterministic QMC points, randomize them times using independently drawn random variables. The integral estimates are unbiased estimates of the true integral with some variance . Averaging over the $latex \hat I_i$ we get another unbiased estimator $latex \hat I$ which has variance . This RQMC variance can be estimated unbiasedly as . If then is the number of samples and this simply is the standard estimate of Monte Carlo variance.
The paper goes on to talk about using what it calls Latin Supercube Sampling for using RQMC in even higher dimensions, again using ANOVA decomposition and RQMC points in each group of interacting variables as determined by the ANOVA.
Overall, I know a bit more about QMC but am still more in the confusion than the knowledge state, which I hope Mathieus next reference will help with.

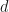

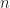

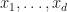

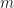

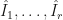
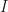
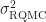
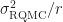



1 thought on “Monte Carlo Extension of Quasi-Monte Carlo”