
This letter to Nature (also on arXiv) by Havlicek and coauthors deals with gaining a quantum computing advantage for classification problems and is written by quantum physicists. The main reason a friend brought this to my attention is that the classification problem is solved using support vector machines, thus fitting my recent interest in reproducing kernel Hilbert space (RKHS) methods.
The main idea is that the way numerical data is encoded into a quantum state can result in a nonlinear feature map into the very high dimensional quantum Hilbert space. Consecutive computation in the quantum Hilbert space then induces nonlinear methods in the input space. In this case nonlinear classification.
The main contributions over papers that are easier to read coming from an RKHS background (such as Quantum machine learning in feature Hilbert spaces by Schuld et al) are twofold. For one, Havlicek and coauthors use a feature map that does not result in a trivial/useless RKHS. Specifically they propose to use two layers of a diagonal gate and a Hadamard gate and conjecture that this gives a quantum advantage (while a single layer can be simulated classically). I am quite lost here of course without any background in quantum computing. Second, their classification algorithm was implemented and run on an actual quantum computer, rather than simulated on standard computers. In particular, they use five superconducting transmons, which seems to be a type of qubit implementation and allows for quantum coupling.
The classification problem they tackle is a toy problem that they construct so as to be perfectly separable with their classification algorithm, which is of course a good sanity check for this first step of developing actual quantum machine learning. The decision of the algorithm for any of the two classes however cannot be read from the computing device deterministically, but only stochastically. The solution, seemingly common in quantum computing, is to read out the class repeatedly to obtain samples and compute their empirical average.
The training then consists of optimizing a bias variable and a parameter 
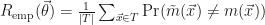
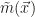
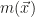

They use two main approaches, one working directly in the space spanned by the 

Personally, I would think that the variational approach makes much more sense in the mid to long term, as the canonical approach does not yield a more powerful method but induces large memory cost for large datasets. Then on the other hand I’m completely lost when thinking about how to invert a matrix in the quantum feature space or compute solutions of systems of linear equations.
Overall, I think that this is a very interesting path to follow and am keen on finding out how quantum computing and machine learning/statistics might combine in beneficial ways.
 be the KME/KDE functional for a density
be the KME/KDE functional for a density  (with respect to reference measure
(with respect to reference measure  ) of distribution
) of distribution 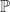 , and assume that this density is in the RKHS. Then
, and assume that this density is in the RKHS. Then 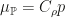 , where
, where 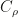 is the covariance operator with respect to the reference measure. Thus we can recover
is the covariance operator with respect to the reference measure. Thus we can recover 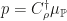 .
. .
.


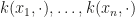 contains the interpolating solution that has minimum RKHS norm. As existing generalization bounds depend on this norm, it’s obvious that this inductive bias is advantageous.
contains the interpolating solution that has minimum RKHS norm. As existing generalization bounds depend on this norm, it’s obvious that this inductive bias is advantageous. 
 denote samples from the prior with density
denote samples from the prior with density  (the
(the 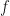 , meaning forecast, is probably owed to Reich having done a lot of Bayesian weather prediction). The idea is to transform these into samples
, meaning forecast, is probably owed to Reich having done a lot of Bayesian weather prediction). The idea is to transform these into samples  that follow the posterior density
that follow the posterior density  (the
(the  meaning analyzed), preferably without introducing unequal weights. Let the likelihood term be denoted by
meaning analyzed), preferably without introducing unequal weights. Let the likelihood term be denoted by 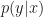 where
where 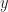 is the data and let
is the data and let  be the normalized importance weight. The normalization in the denominator stems from the fact that in Bayesian inference we can often only evaluate an unnormalized version of the posterior
be the normalized importance weight. The normalization in the denominator stems from the fact that in Bayesian inference we can often only evaluate an unnormalized version of the posterior  .
. , while
, while  . Now we construct a joint probability between the discrete random variables distributed according to
. Now we construct a joint probability between the discrete random variables distributed according to 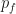 and those distributed according to
and those distributed according to  , i.e. a matrix
, i.e. a matrix 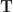 with non-negative entries summing to 1 which has the column sum
with non-negative entries summing to 1 which has the column sum  be the joint pmf induced by
be the joint pmf induced by  under the additional constraint of cyclical monotonicity. This boils down to a linear programming problem. For a fixed prior sample
under the additional constraint of cyclical monotonicity. This boils down to a linear programming problem. For a fixed prior sample 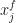 this induces a conditional distribution over the discretely approximated posterior given the discretely approximated prior
this induces a conditional distribution over the discretely approximated posterior given the discretely approximated prior  .
. . Instead, the paper proposes a deterministic transformation using the expected value
. Instead, the paper proposes a deterministic transformation using the expected value 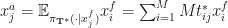 . Reich proves that the mapping
. Reich proves that the mapping  induced by this transformation is such that for
induced by this transformation is such that for  ,
, 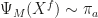 for
for  . In other words, if the ensemble size M goes to infinity, we indeed get samples from the posterior.
. In other words, if the ensemble size M goes to infinity, we indeed get samples from the posterior. Of course, this is not a problem when M is infinite, but my intuition would be that it has a rather strong effect in our finite world. One remedy here would of course be to introduce a rejuvenation step as in SMC, for example moving each particle
Of course, this is not a problem when M is infinite, but my intuition would be that it has a rather strong effect in our finite world. One remedy here would of course be to introduce a rejuvenation step as in SMC, for example moving each particle  using MCMC steps that leave
using MCMC steps that leave  invariant.
invariant. and a proposal density
and a proposal density  . It’s called Operator VI as a fancy way to say that one is flexible in constructing how exactly the objective function uses
. It’s called Operator VI as a fancy way to say that one is flexible in constructing how exactly the objective function uses  and test functions from some family
and test functions from some family  . I completely agree with the motivation: KL-Divergence in the form
. I completely agree with the motivation: KL-Divergence in the form 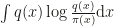 indeed underestimates the variance of $\pi$ and approximates only one mode. Using KL the other way around,
indeed underestimates the variance of $\pi$ and approximates only one mode. Using KL the other way around,  takes all modes into account, but still tends to underestimate variance.
takes all modes into account, but still tends to underestimate variance.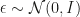 to a bimodal distribution. However their method is not the only one to get bimodality by transforming a standard normal variable and actually the Jacobian correction can be computed even for their suggested transformation! The problem they encounter really is that they throw away one dimension of
to a bimodal distribution. However their method is not the only one to get bimodality by transforming a standard normal variable and actually the Jacobian correction can be computed even for their suggested transformation! The problem they encounter really is that they throw away one dimension of  , which makes the tranformation lose injectivity. However by not throwing the variable away, we keep injectivity and it is possible to compute the density of the transformed variables. The reasons for not accessing the density
, which makes the tranformation lose injectivity. However by not throwing the variable away, we keep injectivity and it is possible to compute the density of the transformed variables. The reasons for not accessing the density 

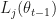 be the loss for the parameter at
be the loss for the parameter at  and jth data point, then the usual batch gradient descent update is
and jth data point, then the usual batch gradient descent update is 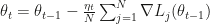 with
with  as step size.
as step size. and uses the update
and uses the update 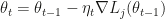 , usually with a decreasing step size
, usually with a decreasing step size 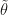 , observe that
, observe that  has an expected value of 0 and is thus a possible control variate. With the possible downside that whenever
has an expected value of 0 and is thus a possible control variate. With the possible downside that whenever  for the individual data points and then shows that the proposed procedure (termed stochastic variance reduced gradient or SVRG) enjoys geometric convergence. Even though the proof uses a slightly odd version of the algorithm, namely where
for the individual data points and then shows that the proposed procedure (termed stochastic variance reduced gradient or SVRG) enjoys geometric convergence. Even though the proof uses a slightly odd version of the algorithm, namely where 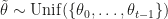 . Rather simply setting
. Rather simply setting  should intuitively improve convergence, but the authors could not report a result on that. Overall a very nice idea, and one that has been discussed in more papers quite a bit, among others by Simon Lacoste-Julien and Francis Bach.
should intuitively improve convergence, but the authors could not report a result on that. Overall a very nice idea, and one that has been discussed in more papers quite a bit, among others by Simon Lacoste-Julien and Francis Bach.
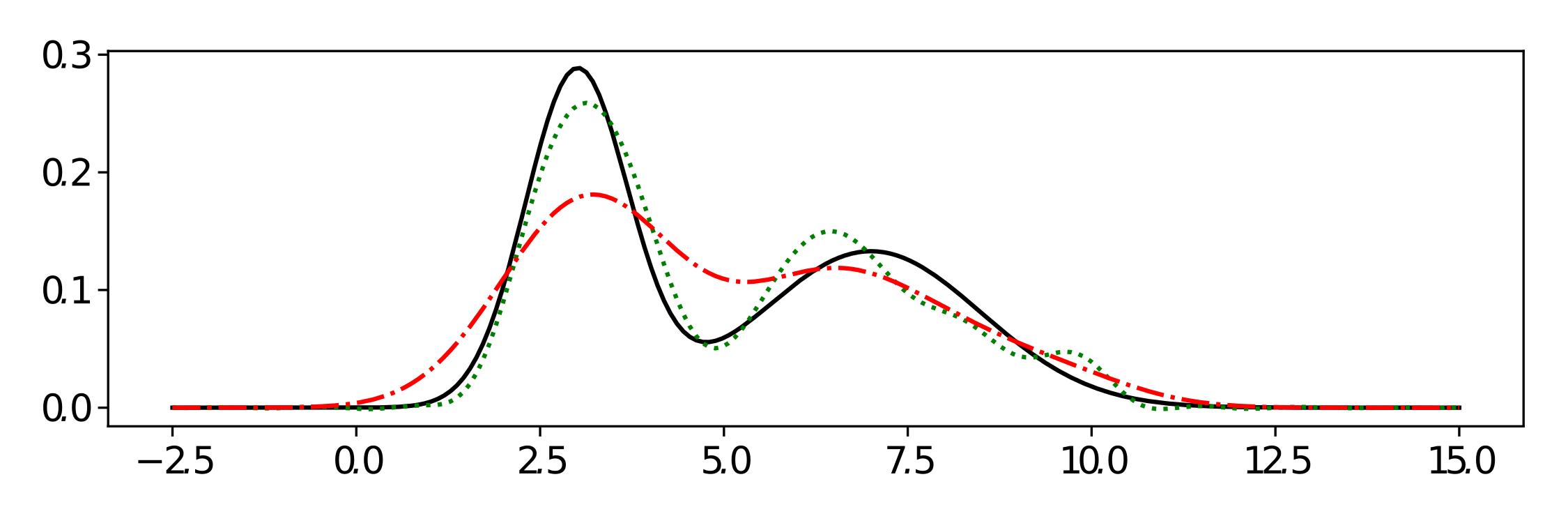
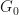 . While the abstract claims their approach works for arbitrary distributions as mixture components, really they make the assumption that the components are well approximated by a Gaussian (of course including distributions arising from sums of RVs because of the CLT). While theoretically NPMLEs might put no constraints on the base measure, practically in the paper first
. While the abstract claims their approach works for arbitrary distributions as mixture components, really they make the assumption that the components are well approximated by a Gaussian (of course including distributions arising from sums of RVs because of the CLT). While theoretically NPMLEs might put no constraints on the base measure, practically in the paper first 
