This NIPS 2016 paper by Ranganath et al. is concerned with Variational Inference using objective functions other than KL-divergence between a target density 



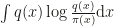

As a particular case, the authors suggest an objective using what they call the Langevin-Stein Operator which does not make use of the proposal density 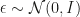

To compute expectations with respect to
