
This letter to Nature (also on arXiv) by Havlicek and coauthors deals with gaining a quantum computing advantage for classification problems and is written by quantum physicists. The main reason a friend brought this to my attention is that the classification problem is solved using support vector machines, thus fitting my recent interest in reproducing kernel Hilbert space (RKHS) methods.
The main idea is that the way numerical data is encoded into a quantum state can result in a nonlinear feature map into the very high dimensional quantum Hilbert space. Consecutive computation in the quantum Hilbert space then induces nonlinear methods in the input space. In this case nonlinear classification.
The main contributions over papers that are easier to read coming from an RKHS background (such as Quantum machine learning in feature Hilbert spaces by Schuld et al) are twofold. For one, Havlicek and coauthors use a feature map that does not result in a trivial/useless RKHS. Specifically they propose to use two layers of a diagonal gate and a Hadamard gate and conjecture that this gives a quantum advantage (while a single layer can be simulated classically). I am quite lost here of course without any background in quantum computing. Second, their classification algorithm was implemented and run on an actual quantum computer, rather than simulated on standard computers. In particular, they use five superconducting transmons, which seems to be a type of qubit implementation and allows for quantum coupling.
The classification problem they tackle is a toy problem that they construct so as to be perfectly separable with their classification algorithm, which is of course a good sanity check for this first step of developing actual quantum machine learning. The decision of the algorithm for any of the two classes however cannot be read from the computing device deterministically, but only stochastically. The solution, seemingly common in quantum computing, is to read out the class repeatedly to obtain samples and compute their empirical average.
The training then consists of optimizing a bias variable and a parameter 
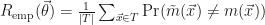
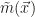
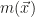

They use two main approaches, one working directly in the space spanned by the 

Personally, I would think that the variational approach makes much more sense in the mid to long term, as the canonical approach does not yield a more powerful method but induces large memory cost for large datasets. Then on the other hand I’m completely lost when thinking about how to invert a matrix in the quantum feature space or compute solutions of systems of linear equations.
Overall, I think that this is a very interesting path to follow and am keen on finding out how quantum computing and machine learning/statistics might combine in beneficial ways.

 and a proposal density
and a proposal density  . It’s called Operator VI as a fancy way to say that one is flexible in constructing how exactly the objective function uses
. It’s called Operator VI as a fancy way to say that one is flexible in constructing how exactly the objective function uses  and test functions from some family
and test functions from some family  . I completely agree with the motivation: KL-Divergence in the form
. I completely agree with the motivation: KL-Divergence in the form 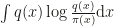 indeed underestimates the variance of $\pi$ and approximates only one mode. Using KL the other way around,
indeed underestimates the variance of $\pi$ and approximates only one mode. Using KL the other way around,  takes all modes into account, but still tends to underestimate variance.
takes all modes into account, but still tends to underestimate variance.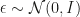 to a bimodal distribution. However their method is not the only one to get bimodality by transforming a standard normal variable and actually the Jacobian correction can be computed even for their suggested transformation! The problem they encounter really is that they throw away one dimension of
to a bimodal distribution. However their method is not the only one to get bimodality by transforming a standard normal variable and actually the Jacobian correction can be computed even for their suggested transformation! The problem they encounter really is that they throw away one dimension of  , which makes the tranformation lose injectivity. However by not throwing the variable away, we keep injectivity and it is possible to compute the density of the transformed variables. The reasons for not accessing the density
, which makes the tranformation lose injectivity. However by not throwing the variable away, we keep injectivity and it is possible to compute the density of the transformed variables. The reasons for not accessing the density 
 , we want to find
, we want to find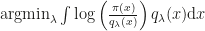

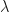 in closed form. In the original paper, the authors suggested the use of the score function as a control variate and a Rao-Blackwellization. Both where described in a way that utterly confused me – until now, because Ruiz, Titsias and Blei manage to describe the concrete application of both control variates and Rao-Blackwellization in a very transparent way. Their own contribution to variance reduction (minus some tricks they applied) is based on the fact that the optimal sampling distribution for estimating
in closed form. In the original paper, the authors suggested the use of the score function as a control variate and a Rao-Blackwellization. Both where described in a way that utterly confused me – until now, because Ruiz, Titsias and Blei manage to describe the concrete application of both control variates and Rao-Blackwellization in a very transparent way. Their own contribution to variance reduction (minus some tricks they applied) is based on the fact that the optimal sampling distribution for estimating  rather than exactly
rather than exactly  . They argue that this optimal sampling distribution is considerably heavier tailed than
. They argue that this optimal sampling distribution is considerably heavier tailed than 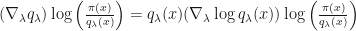 ) vanishes for the modes, making that region irrelevant for gradient estimation. The same should be true for the tails of the distribution I think. Overall very interesting work that I strongly recommend reading, if only to understand the original Blackbox VI proposal.
) vanishes for the modes, making that region irrelevant for gradient estimation. The same should be true for the tails of the distribution I think. Overall very interesting work that I strongly recommend reading, if only to understand the original Blackbox VI proposal.

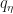 to the target density
to the target density 