
This is an arXival (maybe by now ICML paper?) by Zhang, Shahbaba and Zhao. It suggest fitting an emulator/surrogate 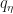

However, that seems to me like reselling the earlier paper by Heiko Strathmann and collaborators on Gradient-free Hamiltonian Monte Carlo with Efficient Kernel Exponential Families. Zhang et al use basically the same idea but fail to look at this earlier work. Their reasoning to use a neural network rather than a GP emulator (computation time) is a bit arbitrary. If you go for a less rich function class (neural network) then the computation time will go down of course – but you would get the same effect by using GPs with inducing points.
Very much lacking to my taste is reasoning for doing the tuning they do. Sometimes they tune HMC/Variational HMC to 85% acceptance, sometimes to 70% acceptance. Also, it seems they not adapting the mass matrix of HMC. If they would, I conjecture the relative efficiency of Standard HMC vs Variational HMC could change drastically. Details on how they tune SGLD is completely lacking.
Overall, I think it is not yet clear what can be learned from the work reported in the paper.
