My friend Patrick Jähnichen asked me to read this AISTATS 2014 paper by Ranganath, Gerrish and Blei. For somebody using mainly variational inference, I guess the prospect of not having to derive an individual algorithm for each new model is very appealing (while for poor sampling Ingmar, it would be very appealing to scale like VI does).
However, I found the paper hard to read and unclear in its conclusions. For the Rao-Blackwellization procedure it is unclear what is conditioned upon in the main paper. I guess it’s the variational parameters of all other components. Similarly, I’m not sure where the first equality in equation (13) stems from, which is crucial for the Control Variate ansatz. These things may just be me.
More problematic I think is their evaluation, especially comparing to MH-within-Gibbs. This is a particularly bad sampling scheme, and I don’t even suggest to use HMC instead. One could easily use a simple Adaptive Metropolis algorithm and still be black box. Also, Rao-Blackwellization can be applied in this pure adaptive MCMC setting as well. Another conservative and black-box possibility would be adaptive SMC by Fearnhead. My intuition is that both variants might actually be better than the suggested Black Box VI or at least the difference in the one performance plot of the paper will barely be noticeable.
However, I think this direction of research is a useful one and I hope they can improve upon the current state.
The Bouncy Particle Sampler (on arXiv) is an advanced MCMC algorithm making use of Gradient information. Initialized at a random position in the support of the target density , and with a random direction (of euclidean length 1), the algorithm proceeds at iteration by moving to where is a random length. The intuitive idea is
the step size/learning rate should be high if the gradient points is similar to (similarity measured by their dot product), low otherwise
after the move, the direction will be updated from using the targets gradient at the new position , by reflecting it on the hyperplane orthogonal to the gradient
At random times, the direction is refreshed to a uniformly drawn direction (without this, no irreducibility). While this algorithm is as mind-boggling as HMC at first reading (for a non-phycisist), it has the nice property that it only has one parameter tuning the frequency with which direction is refreshed, unlike Hamiltonian MC where step-size, number of steps and the Mass-Matrix for momentum have to be tuned. Also, there are no rejections of proposals as HMC (or any other MH based algorithm).
A variant of the algorithm partitions the sampling space when the target is a product of independent factors and there is a direction, position and step size for each factor. Thus, in this version an actual particle system (in the SMC sense) is set up, where the interaction between the particles is achieved by them colliding. Only particles belonging to overlapping factors collide. This part is very interesting but I think it could use a more intuitive exposition to the basic idea.
The paper does not manage to adapt the bouncy sampler to discrete spaces, but shows that one can just apply another MCMC step for the discrete part.
Also, the paper establishes that you can use Hamiltonian dynamics instead of straight line updates, but as far as I can tell the straight line version is used in the numerical experiments. I’m not sure why you would want Hamiltonian dynamics back, as this reintroduces the tuning problems of HMC (maybe less so when using NUTS).
In comparison to NUTS the paper reports that their algorithm performs better (of course). It is not entirely clear however if they used NUTS with adaptation of the mass matrix or without, which should make quite a difference. In their application example (in 10 Dimensions), they seem to not adapt the mass matrix of HMC, which is a pity. A comparison to Adaptive Metropolis with mass matrix and scale adaptation would have been nice, as this is often hard to beat regarding wall clock time. Not to mention its simplicity in implementation.
Overall a very interesting paper, though it doesn’t exactly give an easy exposition. One direction that might be interesting is wether refreshing the direction at random has to be done uniformly over directions. I suppose that it might be possible to do this non-uniformly, for example by drawing a vector from the empirical covariance of the target and normalizing it. But the correctness of this is likely harder to prove. Also, the advantage over HMC in terms of tuning parameters essentially vanishes in that case.


 in the support of the target density
in the support of the target density  , and with a random direction
, and with a random direction  (of euclidean length 1), the algorithm proceeds at iteration
(of euclidean length 1), the algorithm proceeds at iteration 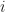 by moving to
by moving to  where
where  is a random length. The intuitive idea is
is a random length. The intuitive idea is should be high if the gradient points is similar to
should be high if the gradient points is similar to  (similarity measured by their dot product), low otherwise
(similarity measured by their dot product), low otherwise will be updated from
will be updated from  , by reflecting it on the hyperplane orthogonal to the gradient
, by reflecting it on the hyperplane orthogonal to the gradient