
The Bouncy Particle Sampler (on arXiv) is an advanced MCMC algorithm making use of Gradient information. Initialized at a random position 


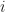


- the step size/learning rate
should be high if the gradient points is similar to
(similarity measured by their dot product), low otherwise
- after the move, the direction
will be updated from
, by reflecting it on the hyperplane orthogonal to the gradient
At random times, the direction
A variant of the algorithm partitions the sampling space when the target is a product of independent factors and there is a direction, position and step size for each factor. Thus, in this version an actual particle system (in the SMC sense) is set up, where the interaction between the particles is achieved by them colliding. Only particles belonging to overlapping factors collide. This part is very interesting but I think it could use a more intuitive exposition to the basic idea.
The paper does not manage to adapt the bouncy sampler to discrete spaces, but shows that one can just apply another MCMC step for the discrete part.
Also, the paper establishes that you can use Hamiltonian dynamics instead of straight line updates, but as far as I can tell the straight line version is used in the numerical experiments. I’m not sure why you would want Hamiltonian dynamics back, as this reintroduces the tuning problems of HMC (maybe less so when using NUTS).
In comparison to NUTS the paper reports that their algorithm performs better (of course). It is not entirely clear however if they used NUTS with adaptation of the mass matrix or without, which should make quite a difference. In their application example (in 10 Dimensions), they seem to not adapt the mass matrix of HMC, which is a pity. A comparison to Adaptive Metropolis with mass matrix and scale adaptation would have been nice, as this is often hard to beat regarding wall clock time. Not to mention its simplicity in implementation.
Overall a very interesting paper, though it doesn’t exactly give an easy exposition. One direction that might be interesting is wether refreshing the direction

Dear Ingmar,
Thank you for your comments! I just wanted to provide some answers to the questions you raised in your post:
– The motivation for following Hamiltonian dynamics is that with respect with certain objectives, they can be done analytically (in particular, for the normal potential). So the idea is to perform the exact Hamiltonian dynamics for the ‘wrong’ normal potential, and correct the discrepancy via occasional bounces.
– While we do not use full matrix adaptation for the HMC baseline, we do use Stan’s default diagonal matrix adaptation (as well as NUTS, adaptation of gamma, delta, kappa, and all the other default adaptations used by Stan). Presumably the authors of Stan use this default since the dense matrix adaptation is computationally very expensive. I will give it a try, but I feel that in the 1000 dimensional examples this will be very slow. We provide in Section 5.4 a comparison of different HMC adaptation and metric configurations. Otherwise, we use Stan’s default options, just as we use the default parameter choice for our method (refreshment rate of 1).
– Regarding mix discrete-continuous space, the scheme we propose in Section 4.1 may look superficially like an MCMC algorithm, but it has the important difference that it preserves the rejection free property: the discrete state stays in one configuration for a random time, and then jumps to a distinct state. We will elaborate on that in the next version of the manuscript.
– One point which I apologize we didn’t make more explicit is that in contrast to what the ‘particle’ part of the name might suggest (and what the Peters and de With paper do), we do not use several particles (in the sense of replicates of the target space) in the local version. Instead, the variables of the local version are different dimensions of the target model.
Thanks again for the nice post!
Best,
Alex
LikeLike
Ah, interesting. I must have been overloaded with physics at that point of reading. But if you follow Hamiltonian Dynamics of a Gaussian Approximation U_0, you could also sample from the Gaussian approximation directly and will get a pretty good sampler. Correction could be done either by using an IS framework instead of MCMC or you could Rao-Blackwellize Metropolis Hastings in the style of Robert & Casella or Douc & Robert if you want to stay in MCMC land.
About full-matrix adaptation: you’re right that this can be slow. Cholesky updates make sense here of course, but also you dont have to update at every sample. If you do it every 100 or 500 samples thats fine and gives strong performance improvements.
One thing I wonder is the following: does rejection-free mean better? Because for MH-style algorithms, higher acceptance rate doesn’t result in optimal diffusion necessarily.
LikeLike