This paper (arXiv) on Bayesian Quadrature with actual theoretical guarantees starts from sigma point rules for approximating integrals. “Sigma point rule” is just a fancy name for using weighted samples, where weights are not constrained in any way (and will actually be negative sometimes in the algorithm).
The basic idea is to approximate the target distribution  as lying in a finite dimensional Reproducing Kernel Hilbert Space and minimize the distance between the approximation
as lying in a finite dimensional Reproducing Kernel Hilbert Space and minimize the distance between the approximation  and (measured using RKHS’ own brand of distribution distance, the Maximum Mean Discrepancy or MMD). This, so far, is an idea that is used in basically all modern methods for numeric integration – variational Bayes and EP of course, but also adaptive MC methods that sample from some
and (measured using RKHS’ own brand of distribution distance, the Maximum Mean Discrepancy or MMD). This, so far, is an idea that is used in basically all modern methods for numeric integration – variational Bayes and EP of course, but also adaptive MC methods that sample from some  at time t then update the proposal to
at time t then update the proposal to 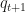 , which should be close to (e.g. a Gaussian approximation in Adaptive Metropolis, or a Mixture of Gaussians or Students with an EM-inspired update in both Andrieu and Moulines 2006 and Cappé et al 2007).
, which should be close to (e.g. a Gaussian approximation in Adaptive Metropolis, or a Mixture of Gaussians or Students with an EM-inspired update in both Andrieu and Moulines 2006 and Cappé et al 2007).
However, the nice thing in this paper is that they actually provide theoretical guarantees that their integral estimates are consistent and converge at rate 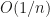 or
or  (where n is the number of samples). While the assumption of lying in a finite dimensional RKHS is to be expected, the stronger assumption is that it has compact support.
(where n is the number of samples). While the assumption of lying in a finite dimensional RKHS is to be expected, the stronger assumption is that it has compact support.
The crucial point seems to me to be the following: while the estimator has a superior rate, picking design points costs 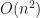 or
or  where n is the number of points. Drawing a sample using Monte Carlo algorithms on the other hand takes constant time, which makes MC linear in the number of points (
where n is the number of points. Drawing a sample using Monte Carlo algorithms on the other hand takes constant time, which makes MC linear in the number of points ( ). This of course is crucial for the wall clock time performance and makes theoretical comparison of MC vs FW Bayesian Quadrature delicate at best.
). This of course is crucial for the wall clock time performance and makes theoretical comparison of MC vs FW Bayesian Quadrature delicate at best.
In the sense of conclusive story for the paper, I think it is a bit unfortunate that for the evaluation the paper uses iid samples directly from in its optimization algorithm. Because if you have these, Monte Carlo estimates are really good as well. But after a nice discussion with the authors, I realized that this does not in any way taint the theoretical results.
I wonder wether it is mostly the idea of extrapolating that gives these good rates, as I think Dan Simpson suggested on Xi’ans blog. And finally, this does not really alleviate the problem that BQ practically works only with Gaussian RBF kernels – which is a rather strong assumption on the smoothness of .
