This 2013 paper by Sebastian Reich in the Journal on Scientific Computing introduces an approach called the Ensemble Transport Particle Filter (ETPF). The main innovation of ETPF, when compared to SMC-like filtering methods, lies in the resampling step. Which is
- based on an optimal transport idea and
- completely deterministic.
No rejuvenation step is used, contrary to the standard in SMC. While the notation is unfamiliar to me, coming from an SMC background, I’ll adopt it here: by  denote samples from the prior with density
denote samples from the prior with density  (the
(the 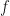 , meaning forecast, is probably owed to Reich having done a lot of Bayesian weather prediction). The idea is to transform these into samples
, meaning forecast, is probably owed to Reich having done a lot of Bayesian weather prediction). The idea is to transform these into samples  that follow the posterior density
that follow the posterior density  (the
(the  meaning analyzed), preferably without introducing unequal weights. Let the likelihood term be denoted by
meaning analyzed), preferably without introducing unequal weights. Let the likelihood term be denoted by 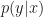 where
where 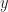 is the data and let
is the data and let  be the normalized importance weight. The normalization in the denominator stems from the fact that in Bayesian inference we can often only evaluate an unnormalized version of the posterior
be the normalized importance weight. The normalization in the denominator stems from the fact that in Bayesian inference we can often only evaluate an unnormalized version of the posterior  .
.
Then the optimal transport idea enters. Given the discrete realizations , is approximated by assigning the discrete probability vector  , while is approximated by the probability vector
, while is approximated by the probability vector  . Now we construct a joint probability between the discrete random variables distributed according to
. Now we construct a joint probability between the discrete random variables distributed according to 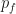 and those distributed according to
and those distributed according to  , i.e. a matrix
, i.e. a matrix 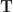 with non-negative entries summing to 1 which has the column sum and row sum (another view would be that is a discrete copula which has prior and posterior as marginals). Let
with non-negative entries summing to 1 which has the column sum and row sum (another view would be that is a discrete copula which has prior and posterior as marginals). Let  be the joint pmf induced by . To qualify as optimal transport, we now seek
be the joint pmf induced by . To qualify as optimal transport, we now seek  under the additional constraint of cyclical monotonicity. This boils down to a linear programming problem. For a fixed prior sample
under the additional constraint of cyclical monotonicity. This boils down to a linear programming problem. For a fixed prior sample 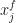 this induces a conditional distribution over the discretely approximated posterior given the discretely approximated prior
this induces a conditional distribution over the discretely approximated posterior given the discretely approximated prior  .
.
We could now simply sample from this conditional to obtain equally weighted posterior samples for each  . Instead, the paper proposes a deterministic transformation using the expected value
. Instead, the paper proposes a deterministic transformation using the expected value 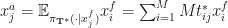 . Reich proves that the mapping
. Reich proves that the mapping  induced by this transformation is such that for
induced by this transformation is such that for  ,
, 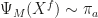 for
for  . In other words, if the ensemble size M goes to infinity, we indeed get samples from the posterior.
. In other words, if the ensemble size M goes to infinity, we indeed get samples from the posterior.
Overall I think this is a very interesting approach. The construction of an optimal transport map based on the discrete approximations of prior and posterior is indeed novel compared to standard SMC. My one objection is that as it stands, the method will only work if the prior support covers all relevant regions of the posterior, as taking the expected value over prior samples will always lead to a contraction.
 Of course, this is not a problem when M is infinite, but my intuition would be that it has a rather strong effect in our finite world. One remedy here would of course be to introduce a rejuvenation step as in SMC, for example moving each particle
Of course, this is not a problem when M is infinite, but my intuition would be that it has a rather strong effect in our finite world. One remedy here would of course be to introduce a rejuvenation step as in SMC, for example moving each particle  using MCMC steps that leave
using MCMC steps that leave  invariant.
invariant.
