This remarkable arXival by Sam Livingstone, Betancourt, Byrne and Girolami takes a look at the conditions under which Hybrid/Hamiltonian Monte Carlo is ergodic wrt a certain distribution 
Whats great about this paper, apart from the results, is how it manages to give the arguments in a rather accessible manner. Considering the depth of the results that is. The ideas are that
- the gradient should at most grow linearly
- for the gradient of
- as we approach infinity, every proposed point thats closer to the origin will be accepted (assumption 4.4.2)
If the gradient grows faster than linear, numerics will punch you in the face. That happened to Heiko Strathmann and me just 5 days ago in a GradientIS-type algorithm, where an estimated gradient had length 

A helpful guidance they provide is the following. For a class of exponential family distributions given by 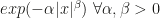


Another thing that caught my eye was their closed form expression for the proposal after 


Which gives me hope that one should be able to compute the proposal probability after any number of leapfrog steps as long as 
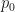


1 thought on “On the Geometric Ergodicity of Hamiltonian Monte Carlo”