
On behalf of the mcqmc 2016 organizing committee I am pleased to accept your proposal.-Art Owen
MCQMC session on Advances in Importance Sampling
The sample size required in Importance Sampling
S. Chatterjee, P. Diaconis
Generalized Multiple Importance Sampling
V. Elvira, L. Martino, D. Luengo, M. Bugallo
Importance Sampling methods are broadly used to approximate posterior distributions or some of their moments. In its standard approach, samples are drawn from a single proposal distribution and weighted properly. However, since the performance depends on the mismatch between the targeted and the proposal distributions, several proposal densities are often employed for the generation of samples. Under this Multiple Importance Sampling (MIS) scenario, many works have addressed the selection or adaptation of the proposal distributions, interpreting the sampling and the weighting steps in different ways. In this paper, we establish a general framework for sampling and weighing procedures when more than one proposal are available. The most relevant MIS schemes in the literature are encompassed within the new framework, and, moreover novel valid schemes appear naturally. All the MIS schemes are compared and ranked in terms of the variance of the associated estimators. Finally, we provide illustrative examples which reveal that, even with a good choice of the proposal densities, a careful interpretation of the sampling and weighting procedures can make a significant difference in the performance of the method.
Continuous-Time Importance Sampling
K. Łatuszyński, G. Roberts, G. Sermaidis, P. Fearnhead
We will introduce a new framework for sequential Monte Carlo, based on evolving a set of weighted particles in continuous time. This framework can lead to novel versions of existing algorithms, such as Annealed Importance Sampling and the Exact Algorithm for diffusions, and can be used as an alternative to MALA for sampling from a target distribution of interest. These methods are amenable to the use of sub-sampling, which can greatly increase their computational efficiency for big-data applications; and can enable unbiased sampling from a much wider-range of target distributions than existing approaches.

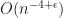 . The transformation being to replace the uniform coordinate
. The transformation being to replace the uniform coordinate  by
by  for
for  and
and  else.
else.