
This NIPS paper by Gotovos, Hassani and Krause deals with coming up with a sampler for submodular models. Submodularity is an interesting concept capturing the concept of diversity/representativeness of a set. A submodular function itself is a function from sets to a real value defined by a diminishing returns property: for 

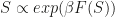
The paper deals with the case of a discrete sampling space. Sampling a set over a discrete domain can be thought of as sampling binary vectors. Speaking of sampling, the reference they give for MCMC is rather obscure. The Gibbs sampler they give is very straight forward: proposing to change one entry in the binary vector at a time. The main contribution of the paper is not the sampler, which is rather straight forward, but rather proving upper bounds on its mixing time, which is 

What I have concluded for myself independent of this paper is that sampling one component at a time often gives a very bad sampler. In this particular case, the sampler is very close to the Gibbs sampler for the Indian Buffer Process, which is mixing rather awfully and one of the reasons why I turned away from the IBP and towards working on sampling algorithms. I don’t see how their sampler might improve here. Also, I’m unsure why they did not cite Sequential Monte Carlo on large binary sampling spaces by Christian Schäfer and Nicolas Chopin – have they been unaware of it? That paper suggests a much more elegant sampler. It adapts to correlations between entries in the binary vector, which is really what you want when doing posterior inference. And the gains of adaptivity are hard to underestimate (as are the perils) – take for example the fact that unadaptive, perfectly tuned HMC is worse than most simple adaptive algorithms, as for example reported in my Gradient IS work or in the Tutorial on adaptive MCMC by Andrieu and Thoms.
