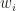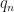A very exiting new preprint by Chatterjee and Diaconis takes a new look at the old Importance Sampling. While its masks as a constructive paper (maybe because of publication bias), its main result to me is actually the deconstruction of an IS myth. Let me elaborate.
The paper shows that the variance estimate for an Importance Sampling estimator is not a good diagnostic for convergence. An implication of this is that aiming for low variance of importance weights, or equivalently high Effective Sample Size, might be better then nothing, but is not actually that great. In more mathy speak, high ESS is a necessary condition for convergence of the estimate, but not a sufficient condition.
Especially in your face is their result that for any 


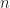
However, they propose a new convergence diagnostic which is basically plagued by a similar problem. They even state themselves that their alternative criterion