
During MCMSki 2016, Heiko mentioned that in high dimensions, the MAP is not a particularly good starting point for a Monte Carlo sampler, because there is no volume around it. I and several people smarter than me where not sure why that could be the case, so Heiko gave us a proof by simulation: he sampled from multivariate standard normals with increasing dimensions and plotted the euclidean norm of the samples. The following is what I reproduced for sampling a standard normal in 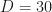
 The histogram has a peak at about
The histogram has a peak at about 

We where dumbstruck by this, but nobody (not even Heiko) had an explanation for what was happening. Yesterday I asked Nicolas about this and he gave the most intuitive interpretation: Given a standard normal variable in 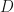






(Title image (c) Niki Odolphie)

Check out the introductory chapter of Giraud, Introduction to High-Dimensional Statistics, CRC, 2015!
LikeLike
Nice! The norm of normally distributed vectors is indeed a chi distribution , hence quasi-constant in our case where the mean is very close to
, hence quasi-constant in our case where the mean is very close to  . That’s why as we increase the dimension and the mean goes farther away from zero the area with non-zero mass appears to be shrinking!
. That’s why as we increase the dimension and the mean goes farther away from zero the area with non-zero mass appears to be shrinking!
https://en.wikipedia.org/wiki/Chi_distribution
which has interestingly a variance of
LikeLike
Nice post!
A note on the Chi2: http://goo.gl/Sghwc4
Just wanted to add one thing, to clarify what I meant.
Using the MAP to initialise an MCMC run is not the best idea ever, but it also it not really a bad idea. Any (converging) sampler will eventually move to the typical set. So the worst thing that can happen is to loose a bit of computing power when in moving from the MAP to the typical set. If your sampler is geometrically ergodic for example, it will do so at a geometric rate — from *any* starting point. You can easily see that if you use a RWMH on a high dimensional Gaussian and start it at the mode — the traces will (slowly in high dimensions) move to the sphere you were talking about in the blog post.
What *is* a bad idea in high dimensions, however, is to use the MAP to represent your probability distribution. That is, MAP point estimates, when used to summarise a model give a quite different answer to using a single sample from the posterior. If you do a Gaussian linear regression in high dimensions, and compare the predictive posterior using MAP and MCMC, you will see.
LikeLike
Isn’t this observation simply that neighbourhoods are smaller in high dimensions than we might intuitively suppose? For a Normal in high dimensions the mean/mode/map remains the point at which samples are typically nearest; there isn’t a starting point closer to the mass, right?
e.g. D=30; N=1000; X <- matrix(rnorm(D*N),nrow=D,ncol=N); hist(sqrt(colSums((X)^2)),col="black"); for (i in 1:10) {R = 2*i/D; hist(sqrt(colSums((X-R)^2)),add=T,border=hsv(i/10*0.6),plot.new=F)}
LikeLike
Yes, the mean is the one point that has the shortest distance to the sphere in which the posterior mass concentrates.
sphere in which the posterior mass concentrates. , a good starting point would be in that
, a good starting point would be in that  sphere, not at the mean. An intuition could be that you actually start from equilibrium in that case, i.e.
sphere, not at the mean. An intuition could be that you actually start from equilibrium in that case, i.e.  , instead of having to converge first.
, instead of having to converge first. where the current point doesn’t matter.
where the current point doesn’t matter.
However, for several Markovian proposal kernels
Obviously, there are exceptions, the easiest being when using an independent proposal
LikeLike
Interesting perspective; I disagree of course: I don’t think one is any closer to equilibrium for a RW MCMC by starting in the sphere than at the MAP, it just looks that way when you collapse the parameter space (arbitrarily) down to a single radial axis.
LikeLike
Well, this so-called sphere has actually a massive volume, that’s why it aggregates so much probability mass even though the density decreases. In high dimension there is no point, including the MAP, that summarizes the whole distribution well. But there is also no point better than the MAP. Do the same plot again with another point as the origin …
LikeLike
Then the expected distance from that other point will be higher of course. Which reiterates Ewans point, but makes it more intuitive (to me).
LikeLike