
This is a rather old JASA paper by Siddhartha Chib and Ivan Jeliazkov from 2001. I dug it up again as I am frantically trying to get my contribution for the CRiSM workshop on Estimating Constants in shape. My poster will be titled Flyweight evidence estimates as it looks at methods for estimating model evidence (aka marginal likelihood, normalizing constant, free energy) that are computationally very cheap when a sample from the target/posterior distribution exists.
I noticed again that the approach by Chib & Jeliazkov (2001) does not satisfy this constraint, although they claim otherwise in the paper. The estimator is based on the fact that the normalized probability of a point 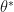
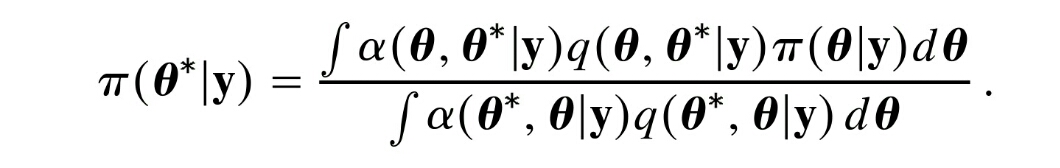
where 

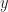


Now the integral in the numerator is cheap to estimate when we already have samples from 

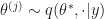
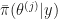
I already included that criticism in my PhD thesis, but when revising under time pressure I no longer thought it was valid and erroneously took it out.
