This interesting paper by Srivastava, Greff and Schmidhuber (arxiv) looks at the problem of enabling deeper architectures for neural networks. The main argument being that Neural Networks have become successful mainly because training deeper architectures has only recently become possible – and making them deeper might only improve performance. However, performance tends to plateau in conventional deep architectures, as exemplified by their first plot.
The proposed solution to training deeper architectures is to simply introduce a gaiting architecture similar to LSTM ideas. If a normal layer is defined by 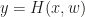 for output y, input x and parametrization of the layer given by w, a highway layer is simply given by
for output y, input x and parametrization of the layer given by w, a highway layer is simply given by 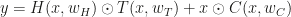 , where T and C (Transfer and Carry, respectively) are functions with a (co)domain of the same dimensionality as x and y. This is called a highway layer, as gradient infomation supposedly travels faster along the $latexx \odot C(x, w_C)$ part (hence the Autobahn illustration). When it is required to change dimensionality, one has to resort to a normal layer, or subsample/pad.
, where T and C (Transfer and Carry, respectively) are functions with a (co)domain of the same dimensionality as x and y. This is called a highway layer, as gradient infomation supposedly travels faster along the $latexx \odot C(x, w_C)$ part (hence the Autobahn illustration). When it is required to change dimensionality, one has to resort to a normal layer, or subsample/pad.
Now this archictecture of the highway layer of course allows for gradient information in SGD to travel two paths, one trough  , one through
, one through  and the output of a layer is a combination of the input of the layer x and the output of
and the output of a layer is a combination of the input of the layer x and the output of  . The authors use a logistic model
. The authors use a logistic model 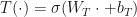 and
and  . The authors biased towards simply carrying information through without transformation, which in their setup means simply
. The authors biased towards simply carrying information through without transformation, which in their setup means simply 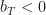 . After training the network with SGD an looking at the value of the transform gates of different layers, they find that those are closed on average (Figure 2, second column) while exhibiting large variance across inputs (exemplified by the transform gate outputs of a single sample, Figure 2, third column). Interestingly, some dimensions of the input to the network are carried through right to the last layer.
. After training the network with SGD an looking at the value of the transform gates of different layers, they find that those are closed on average (Figure 2, second column) while exhibiting large variance across inputs (exemplified by the transform gate outputs of a single sample, Figure 2, third column). Interestingly, some dimensions of the input to the network are carried through right to the last layer.
They find that this architecture not only helps to train larger networks, but also aids actually utilizing deeper architectures. So this paper took a similar inception as LSTMs: tries to solve an inference problem and comes up with a model that is more powerful in a way.
I feel that the result is somehow odd: carrying the input information through can be achieved by setting the weights in the original normal layer  accordingly (if it is fully connected that is). Why does adding the extra complexity gain so much? I do not feel the paper addressing this important question and I can only speculate myself: perhaps the transform/carry architecture is effective because its weights lie on a compact manifold (because of the logistic transform). Maybe the problem becomes better conditioned because simple downscaling of the input is done by T, while H takes care of actual transformations. To check this, it would have been interesting to know whether they used any constraints on the weights of H – if they haven’t, and H is fully connected, the better conditioning might be an actual explanation. In that case, simply constraining the weights
accordingly (if it is fully connected that is). Why does adding the extra complexity gain so much? I do not feel the paper addressing this important question and I can only speculate myself: perhaps the transform/carry architecture is effective because its weights lie on a compact manifold (because of the logistic transform). Maybe the problem becomes better conditioned because simple downscaling of the input is done by T, while H takes care of actual transformations. To check this, it would have been interesting to know whether they used any constraints on the weights of H – if they haven’t, and H is fully connected, the better conditioning might be an actual explanation. In that case, simply constraining the weights  of H (mapping input
of H (mapping input  to the same output dimension
to the same output dimension  ) in an appropriate way might have similar effects.
) in an appropriate way might have similar effects.
EDIT: After talking to the authors, I realized where my thinking was insufficient: the layer H inside the highway always used a nonlinear map. The gating allowed to switch that off. I guess thats the difference from reading about NNs to using them…

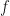

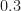 (this threshold being motivated in the paper), the algorithm is done.
(this threshold being motivated in the paper), the algorithm is done.
 some function F is submodular if
some function F is submodular if  . For a probabilistic model one can use such an F by defining a probability of a set as
. For a probabilistic model one can use such an F by defining a probability of a set as 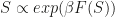 . Because of the diminishing returns, this results in a distribution where points are repulsive and tend to spread out over the space rather than clump together, just like in Low Discrepancy Point Sets used for QMC. Think Determinantal Point Process, which is log-submodular and has also been called the Antisocial Coffeshop Process, or, evocatively, the Urinal Process (thanks to Vinayak Rao for this 😀 ).
. Because of the diminishing returns, this results in a distribution where points are repulsive and tend to spread out over the space rather than clump together, just like in Low Discrepancy Point Sets used for QMC. Think Determinantal Point Process, which is log-submodular and has also been called the Antisocial Coffeshop Process, or, evocatively, the Urinal Process (thanks to Vinayak Rao for this 😀 ). if the base set from which we can add/remove points is of cardinality n. If adding/removing a point only has an certain effect on the submodular function bounded by 1, then the sampler mixes at least in time
if the base set from which we can add/remove points is of cardinality n. If adding/removing a point only has an certain effect on the submodular function bounded by 1, then the sampler mixes at least in time  . I have no intuition wether this improved result is obtained under realistic assumptions.
. I have no intuition wether this improved result is obtained under realistic assumptions.

 , one can find a number of samples n such that
, one can find a number of samples n such that  where
where  is the empirical variance of
is the empirical variance of 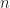 samples, independent of your target density and your proposal distribution. Think about this: I don’t care about your actual integration problem or your proposal distribution. Just tell me what estimator variance you are willing to accept and I will tell you a number of samples that will exhibit lower variance with high probability. This is, in their words, absurd as a diagnostic.
samples, independent of your target density and your proposal distribution. Think about this: I don’t care about your actual integration problem or your proposal distribution. Just tell me what estimator variance you are willing to accept and I will tell you a number of samples that will exhibit lower variance with high probability. This is, in their words, absurd as a diagnostic. (where the
(where the 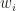 are the importance weights) being close to 0 can be proofed to be necessary but not sufficient. Just stating that ESS isn’t great is not a great sell for some reviewers so they have to come up with an alternative – and conjecture that it is sufficient, while not being able to proof it. Anyway
are the importance weights) being close to 0 can be proofed to be necessary but not sufficient. Just stating that ESS isn’t great is not a great sell for some reviewers so they have to come up with an alternative – and conjecture that it is sufficient, while not being able to proof it. Anyway 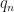 might still be a better diagnostic than ESS and all things considered this is a wonderful piece of research.
might still be a better diagnostic than ESS and all things considered this is a wonderful piece of research.![\hat \mu[X] = \sum_{x \in X} \alpha(x) k(\cdot,x)](https://s0.wp.com/latex.php?latex=%5Chat+%5Cmu%5BX%5D+%3D+%5Csum_%7Bx+%5Cin+X%7D+%5Calpha%28x%29+k%28%5Ccdot%2Cx%29&bg=ffffff&fg=141412&s=0&c=20201002) for pd kernel k becomes an IS estimator with the constraint imposed in the paper (that
for pd kernel k becomes an IS estimator with the constraint imposed in the paper (that  ) and one additional assumption (
) and one additional assumption ( ). Also, when using their method with sparse representations (in the paragraph “More general expansions sets” making the assumption
). Also, when using their method with sparse representations (in the paragraph “More general expansions sets” making the assumption  and
and 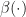 . Those conditions unfortunately being incompatible with the assumption that weights are independent of samples.
. Those conditions unfortunately being incompatible with the assumption that weights are independent of samples.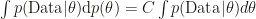 , where C is some constant that can be anything because
, where C is some constant that can be anything because 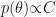 is always a correct characterization of the improper prior. In the other experiments, a statement on whether the prior is proper or improper is absent.
is always a correct characterization of the improper prior. In the other experiments, a statement on whether the prior is proper or improper is absent. as lying in a finite dimensional Reproducing Kernel Hilbert Space and minimize the distance between the approximation
as lying in a finite dimensional Reproducing Kernel Hilbert Space and minimize the distance between the approximation  and
and  at time t then update the proposal to
at time t then update the proposal to 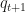 , which should be close to
, which should be close to 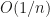 or
or  (where n is the number of samples). While the assumption of
(where n is the number of samples). While the assumption of 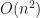 or
or  where n is the number of points. Drawing a sample using Monte Carlo algorithms on the other hand takes constant time, which makes MC linear in the number of points (
where n is the number of points. Drawing a sample using Monte Carlo algorithms on the other hand takes constant time, which makes MC linear in the number of points ( ). This of course is crucial for the wall clock time performance and makes theoretical comparison of MC vs FW Bayesian Quadrature delicate at best.
). This of course is crucial for the wall clock time performance and makes theoretical comparison of MC vs FW Bayesian Quadrature delicate at best.