This is an important arXival by Alain Durmus and Eric Moulines. The title is slightly optimized for effect, as the paper actually contains non-asymptotic and asymptotic analysis.
The basic theme of the paper is in getting upper bounds on total variation (and more general distribution distances) between an uncorrected discretized Langevin diffusion wrt some target  and itself. The discretization used is the common scheme with the scary name Euler-Maruyama:
and itself. The discretization used is the common scheme with the scary name Euler-Maruyama:
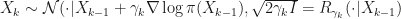
Under a Foster-Lyapunov condition,  is a Markov kernel that admits a unique stationary distribution
is a Markov kernel that admits a unique stationary distribution  that is close to the desired in total variation distance and gets closer when
that is close to the desired in total variation distance and gets closer when  decreases.
decreases.
Now in the non-asymptotic case with fixed  , the authors provide bounds that explicitly depend on dimensionality of the support of the target, the number of samples drawn and the chosen step size
, the authors provide bounds that explicitly depend on dimensionality of the support of the target, the number of samples drawn and the chosen step size  . Unfortunately, these bounds contain some unknowns as well, such as the Lipschitz constant
. Unfortunately, these bounds contain some unknowns as well, such as the Lipschitz constant 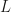 of the gradient of the logpdf
of the gradient of the logpdf  and some suprema that I am unsure how to get explicitly.
and some suprema that I am unsure how to get explicitly.
Durmus and Moulines particularly take a look at scaling with dimension under increasingly strong conditions on , getting exponential (in dimension) constants for the convergence when is superexponential outside a ball. Better convergence can be achieved when assuming to be log-concave or strongly log-concave. This is not surprising, nevertheless the theoretical importance of the results is clear from the fact that together with Arnak Dalalyan this is the first time that results are given for the ULA after the Roberts & Tweedie papers from 1996.
As a practitioner, I would have wished for very explicit guidance in picking or the series  . But hopefully with Alains paper as a foundation that can be the next step. As a non-mathematician, I had some problems in following the paper and at some point I completely lost it. This surely is in part due to the quite involved content. However, one might still manage to give intuition even in this case, as Sam Livingstones recent paper on HMC shows. I hope Alain goes over it again with readability and presentation in mind so that it will get the attention it deserves. Yet another task for something that already took a lot of work…
. But hopefully with Alains paper as a foundation that can be the next step. As a non-mathematician, I had some problems in following the paper and at some point I completely lost it. This surely is in part due to the quite involved content. However, one might still manage to give intuition even in this case, as Sam Livingstones recent paper on HMC shows. I hope Alain goes over it again with readability and presentation in mind so that it will get the attention it deserves. Yet another task for something that already took a lot of work…
(photo: the Lipschitz Grill diner in Berlin – I don’t
know about their food, but the name is remarkable)


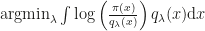
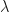



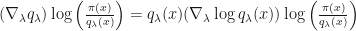


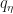 to the target density
to the target density 

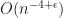 . The transformation being to replace the uniform coordinate
. The transformation being to replace the uniform coordinate  by
by  for
for  and
and  else.
else.
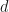 dimensional integrand which does not live on a lower dimensional manifold, and only use
dimensional integrand which does not live on a lower dimensional manifold, and only use  . Then equidistributing these
. Then equidistributing these 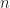 points meaningfully in becomes impossible. Of course if the integrand does live on a lower dimensional manifold, one can use that fact to get convergence rates that correspond to the dimensionality of that manifold, which corresponds (informally) to what Art Owen calls effective dimension. Two definitions of effective dimension variants are given, both using the ANOVA decomposition. ANOVA only crossed my way earlier through my wifes psychology courses in stats, where it seemed to be a test mostly, so I’ll have delve more deeply into the decomposition method. It seems that basically, the value of the integrand
points meaningfully in becomes impossible. Of course if the integrand does live on a lower dimensional manifold, one can use that fact to get convergence rates that correspond to the dimensionality of that manifold, which corresponds (informally) to what Art Owen calls effective dimension. Two definitions of effective dimension variants are given, both using the ANOVA decomposition. ANOVA only crossed my way earlier through my wifes psychology courses in stats, where it seemed to be a test mostly, so I’ll have delve more deeply into the decomposition method. It seems that basically, the value of the integrand  is treated as a dependent variable while the
is treated as a dependent variable while the 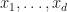 are the independent variables and ANOVA is used to get an idea of how independent variables interact in producing the dependent variable. In which case of course we would have to get some meaningful samples of points
are the independent variables and ANOVA is used to get an idea of how independent variables interact in producing the dependent variable. In which case of course we would have to get some meaningful samples of points  which currently seems to me like circling back to the beginning, since meaningful samples are what we want in the first place.
which currently seems to me like circling back to the beginning, since meaningful samples are what we want in the first place.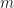 of deterministic QMC points, randomize them
of deterministic QMC points, randomize them  times using independently drawn random variables. The integral estimates
times using independently drawn random variables. The integral estimates 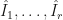 are unbiased estimates of the true integral
are unbiased estimates of the true integral 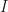 with some variance
with some variance 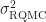 . Averaging over the $latex \hat I_i$ we get another unbiased estimator $latex \hat I$ which has variance
. Averaging over the $latex \hat I_i$ we get another unbiased estimator $latex \hat I$ which has variance 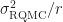 . This RQMC variance can be estimated unbiasedly as
. This RQMC variance can be estimated unbiasedly as  . If
. If  then
then 
 and led to Nirvana. If not the estimation is the problem but the actual gradient, of course you have the same effect. The second assumption is also very intuitive: if the gradient leads into the tails, then it hurts rather than helps convergence. And your posterior is improper. The final assumption basically requires that your chance to improve by proposing a point closer to the origin goes to
and led to Nirvana. If not the estimation is the problem but the actual gradient, of course you have the same effect. The second assumption is also very intuitive: if the gradient leads into the tails, then it hurts rather than helps convergence. And your posterior is improper. The final assumption basically requires that your chance to improve by proposing a point closer to the origin goes to  the further you move away from it.
the further you move away from it.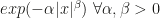 , whenever the tails of the distribution are no heavier than Laplace (
, whenever the tails of the distribution are no heavier than Laplace ( ) and no thinner than Gaussian (
) and no thinner than Gaussian ( ), HMC will be geometrically ergodic. In all other cases, it won’t.
), HMC will be geometrically ergodic. In all other cases, it won’t. , eq. (13):
, eq. (13):
 is invertible and thus a Jacobian exists to account for the transformation of
is invertible and thus a Jacobian exists to account for the transformation of 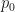 hidden in the
hidden in the  . A quick check with
. A quick check with 

 of the Markov Chain, the final MH proposal
of the Markov Chain, the final MH proposal  is constructed using an intermediate step
is constructed using an intermediate step  , where the intermediate step is encouraged to have lower density than
, where the intermediate step is encouraged to have lower density than  involves computing an intractable integral, as one has to integrate away the intermediate downhill move. They get around this by introducing an auxiliary variable, a technique inspired by Møller et al. (2006), where it was used to get around the computation of normalizing constants. I discussed a similar idea shortly with Jeff Miller (
involves computing an intractable integral, as one has to integrate away the intermediate downhill move. They get around this by introducing an auxiliary variable, a technique inspired by Møller et al. (2006), where it was used to get around the computation of normalizing constants. I discussed a similar idea shortly with Jeff Miller (
 . The weights of the samples drawn from these are Rao-Blackwellized using the deterministic mixture idea of Zhou and Owen, and as far as I can see only the Importance Samples are used for estimating integrands.
. The weights of the samples drawn from these are Rao-Blackwellized using the deterministic mixture idea of Zhou and Owen, and as far as I can see only the Importance Samples are used for estimating integrands.

{kind=link}
{kind=link}