This remarkable arXival by Sam Livingstone, Betancourt, Byrne and Girolami takes a look at the conditions under which Hybrid/Hamiltonian Monte Carlo is ergodic wrt a certain distribution  , and, in a second step, under which it will converge in total variation at a geometric rate. A nice feature being that they even prove that setting the integration time dynamically can lead to the sampler yielding geometric rate for a larger class of targets. Under idealized conditions for the dynamic integration time and, admittedly, in a certain exponential family.
, and, in a second step, under which it will converge in total variation at a geometric rate. A nice feature being that they even prove that setting the integration time dynamically can lead to the sampler yielding geometric rate for a larger class of targets. Under idealized conditions for the dynamic integration time and, admittedly, in a certain exponential family.
Whats great about this paper, apart from the results, is how it manages to give the arguments in a rather accessible manner. Considering the depth of the results that is. The ideas are that
- the gradient should at most grow linearly
- for the gradient of to be of any help, it cannot lead further into the tails of the distribution or vanish (both assumption 4.4.1)
- as we approach infinity, every proposed point thats closer to the origin will be accepted (assumption 4.4.2)
If the gradient grows faster than linear, numerics will punch you in the face. That happened to Heiko Strathmann and me just 5 days ago in a GradientIS-type algorithm, where an estimated gradient had length  and led to Nirvana. If not the estimation is the problem but the actual gradient, of course you have the same effect. The second assumption is also very intuitive: if the gradient leads into the tails, then it hurts rather than helps convergence. And your posterior is improper. The final assumption basically requires that your chance to improve by proposing a point closer to the origin goes to
and led to Nirvana. If not the estimation is the problem but the actual gradient, of course you have the same effect. The second assumption is also very intuitive: if the gradient leads into the tails, then it hurts rather than helps convergence. And your posterior is improper. The final assumption basically requires that your chance to improve by proposing a point closer to the origin goes to  the further you move away from it.
the further you move away from it.
A helpful guidance they provide is the following. For a class of exponential family distributions given by 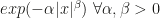 , whenever the tails of the distribution are no heavier than Laplace (
, whenever the tails of the distribution are no heavier than Laplace ( ) and no thinner than Gaussian (
) and no thinner than Gaussian ( ), HMC will be geometrically ergodic. In all other cases, it won’t.
), HMC will be geometrically ergodic. In all other cases, it won’t.
Another thing that caught my eye was their closed form expression for the proposal after 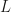 leapfrog steps with stepsize
leapfrog steps with stepsize  , eq. (13):
, eq. (13):

Which gives me hope that one should be able to compute the proposal probability after any number of leapfrog steps as long as  is invertible and thus a Jacobian exists to account for the transformation of
is invertible and thus a Jacobian exists to account for the transformation of  hidden in the
hidden in the  . A quick check with given by a bayesian posterior shows that this might not be trivial however.
. A quick check with given by a bayesian posterior shows that this might not be trivial however.

 where
where  is the old momentum, and we mix it with another Gaussian RV of the same distribution
is the old momentum, and we mix it with another Gaussian RV of the same distribution  for some parameter
for some parameter  . We recover HMC for
. We recover HMC for  , as in that case the momentum is always refreshed.
, as in that case the momentum is always refreshed.


 of the Markov Chain, the final MH proposal
of the Markov Chain, the final MH proposal  is constructed using an intermediate step
is constructed using an intermediate step  , where the intermediate step is encouraged to have lower density than
, where the intermediate step is encouraged to have lower density than 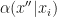 involves computing an intractable integral, as one has to integrate away the intermediate downhill move. They get around this by introducing an auxiliary variable, a technique inspired by Møller et al. (2006), where it was used to get around the computation of normalizing constants. I discussed a similar idea shortly with Jeff Miller (
involves computing an intractable integral, as one has to integrate away the intermediate downhill move. They get around this by introducing an auxiliary variable, a technique inspired by Møller et al. (2006), where it was used to get around the computation of normalizing constants. I discussed a similar idea shortly with Jeff Miller (
 . The weights of the samples drawn from these are Rao-Blackwellized using the deterministic mixture idea of Zhou and Owen, and as far as I can see only the Importance Samples are used for estimating integrands.
. The weights of the samples drawn from these are Rao-Blackwellized using the deterministic mixture idea of Zhou and Owen, and as far as I can see only the Importance Samples are used for estimating integrands.

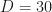 dimensions.
dimensions. The histogram has a peak at about
The histogram has a peak at about  , which means most of the samples are in a sphere around the mean/mode/MAP of the target distribution and none are at the MAP, which would correspond to norm
, which means most of the samples are in a sphere around the mean/mode/MAP of the target distribution and none are at the MAP, which would correspond to norm  .
. dimensions,
dimensions,  , computing the euclidean norm you get
, computing the euclidean norm you get  . But as
. But as  is gaussian, this just means
is gaussian, this just means  has a
has a  distribution, which results in the expected value
distribution, which results in the expected value  . Voici l’explication.
. Voici l’explication.
 However, this of course comes at the price of higher computational complexity, similar to related methods such as Riemannian Manifold MALA/HMC. If your dataset is large however and evaluating the likelihood majorizes evaluating the Gram matrix on your particle system, this method will still have an edge over others when the support is nonlinear. For the MCMC predecessor KAMH/Kameleon see
However, this of course comes at the price of higher computational complexity, similar to related methods such as Riemannian Manifold MALA/HMC. If your dataset is large however and evaluating the likelihood majorizes evaluating the Gram matrix on your particle system, this method will still have an edge over others when the support is nonlinear. For the MCMC predecessor KAMH/Kameleon see 
 . Now what is the inverse step when you only know
. Now what is the inverse step when you only know 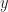 but not
but not  ? It doesn’t exist in general). Which makes the very basis of the method unsound. Max answered that one can still compute the Jacobian in certain cases, even if the inverse function doesn’t exist. For some reason I wasn’t able to counter that on the spot. Of course, you can always compute the Jacobian of the forward transformation, but you don’t need that Jacobian. The Jacobian that you need is that of the inverse function. See Theorem 12.7 in Jacod & Protter for example.
? It doesn’t exist in general). Which makes the very basis of the method unsound. Max answered that one can still compute the Jacobian in certain cases, even if the inverse function doesn’t exist. For some reason I wasn’t able to counter that on the spot. Of course, you can always compute the Jacobian of the forward transformation, but you don’t need that Jacobian. The Jacobian that you need is that of the inverse function. See Theorem 12.7 in Jacod & Protter for example.
 The basic idea is to use character level ConvNets (with a pooling operation over time), extract features using the recently proposed autobahn networks (
The basic idea is to use character level ConvNets (with a pooling operation over time), extract features using the recently proposed autobahn networks (
{kind=link}
{kind=link}