This arXival by Mandt, Hoffman and Blei from February takes a look at what they call SGD with constant learning rate or constant SGD. Which is not really Stochastic Gradient Descent anymore, but rather a sampling algorithm, as we should bounce around the mode of the posterior rather than converging to it. Consequently they interpret constant SGD as a stochastic process in discrete time with some stationary distribution. They go on to analyse it under the assumption that the stationary distribution is Gaussian (Assumption 1 and 4). Something that springs to my mind here is the following: even if we accept that the stationary distribution of the process might be Gaussian (intuitively, not rigorously), what guarantees that the stationary distribution is the posterior? Even if the posterior is also gaussian, it could have a different (co)variance. I think a few more words about this question might be good. In particular, without adding artificial noise, is it guaranteed that every point in the posteriors domain can be reached with non-zero probability? And can be reached an infinite number of times if we collect infinite samples? If not, the constant SGD process is transient and does not enjoy good stability properties.
Another delicate point hides in Assumption 1: As our stochastic gradient is the sum of independent RVs, the CLT is invoked to assume that the gradient noise is Gaussian. But the CLT might not yet take effect if the number of data points in our subsample is small, which is the very thing one would like in order to have advantages in computation time. This of course is yet another instance of the dilemma common to all scalable sampling techniques, and at this stage of research this is not a show stopper.
Now assuming that constant SGD is not transient and it has a stationary distribution that is the posterior and that the posterior or its dominant mode is approximately Gaussian, we can of course try to optimize the parameters of constant SGD to make the sample it produces as close a possible to a posterior sample. Which the authors conveniently do using an Ornstein-Uhlenbeck approximation, which has a Gaussian stationary distribution. Their approach is to minimize KL-Divergence between the OU approximation and the posterior, and derive optimal parameter settings for constant SGD in closed form. The most interesting part of the theoretical results section probably is the one on optimal preconditioning in Stochastic Gradient Fisher Scoring, as that sampler adds artificial noise. Which might solve some of the transience questions.
The presentation would gain a lot by renaming “constant SGD” for what it is – a sampling algorithm. The terminology and notation in general are sometimes a bit confusing, but nothing a revision can’t fix. In general, the paper presents an interesting approach to deriving optimal parameters for a class of algorithms that is notoriously hard to tune. This is particularly relevant because the constant step size could improve mixing considerably over Welling & Tehs SGLD. What would be interesting to see is wether the results could be generalized to the case where the posterior is not Gaussian. For practical reasons, because stochastic VB/EP works quite well in the gaussian case. For theoretical reasons, because EP now even comes with some guarantees (haven’t read that paper admittedly). Maybe a path would be to take a look at the Gaussian approximation to a multimodal posterior spanning all modes, and minimizing KL-Divergence between that and the OU process. Or maybe one can proof that constant SGD (with artificial noise?) has some fixed stationary distribution to which stochastic drift term plus noise are a Markov Kernel, which might enable a pseudo-marginal correction.
 With my son, my niece, sister and her boyfriend I visited the science museum in Mannheim about two months ago. There where many nice experiments, and as a (former ?) computer scientist I was particularly impressed by Leibniz’ mechanical digital calculator, completed in the 17th century and able to do all four basic arithmetic operations. This of course is another example for the superiority of Leibniz over Newton…
With my son, my niece, sister and her boyfriend I visited the science museum in Mannheim about two months ago. There where many nice experiments, and as a (former ?) computer scientist I was particularly impressed by Leibniz’ mechanical digital calculator, completed in the 17th century and able to do all four basic arithmetic operations. This of course is another example for the superiority of Leibniz over Newton…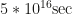





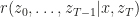 where
where  is the data, and
is the data, and 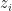 are the samples from Monte Carlo. This distribution is named auxiliary inference distribution at one place and inverse model further down in the same column. This is one example of notation/terminology changing in the paper. I have little intuition as to what
are the samples from Monte Carlo. This distribution is named auxiliary inference distribution at one place and inverse model further down in the same column. This is one example of notation/terminology changing in the paper. I have little intuition as to what  is used for or why it is interesting to look at. An elementary explanation would be nice here.
is used for or why it is interesting to look at. An elementary explanation would be nice here.
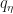 to the target density
to the target density  via score matching and then use the gradients of
via score matching and then use the gradients of 


