Yesterday, the MCqMC 2016 conference started, which I am unfortunately not attending – the program looks very interesting! Tomorrow, Nicolas Chopin will chair the session on importance sampling that I organized.
Advances in Importance Sampling
Wednesday August 17th 10:25–11:55, Berg B
Recently, there has been renewed interest in Importance Sampling, with results that go far beyond the state of the art of the early nineties when research focus shifted to MCMC. These results include theoretical advances in the analysis of convergence conditions and convergence assessment on one side. On the other, an overarching Multiple Importance Sampling framework has been proposed as well as IS based on piecewise deterministic processes, which allows, amongst other things, data subsampling and incorporating gradient information.
Generalized Multiple Importance Sampling
V. Elvira
Importance sampling methods are broadly used to approximate posterior distributions or some of their moments. In its standard approach, samples are drawn from a single proposal distribution and weighted properly. However, since the performance depends on the mismatch between the targeted and the proposal distributions, several proposal densities are often employed for the generation of samples. Under this Multiple Importance Sampling (MIS) scenario, many works have addressed the selection or adaptation of the proposal distributions, interpreting the sampling and the weighting steps in different ways. In this paper, we establish a novel general framework for sampling and weighting procedures when more than one proposal is available. The most relevant MIS schemes in the literature are encompassed within the new framework, and, moreover novel valid schemes appear naturally. All the MIS schemes are compared and ranked in terms of the variance of the associated estimators. Finally, we provide illustrative examples which reveal that, even with a good choice of the proposal densities, a careful interpretation of the sampling and weighting procedures can make a significant difference in the performance of the method. Joint work with L. Martino (University of Valencia), D. Luengo (Universidad Politecnica de Madrid) and M. F. Bugallo (Stony Brook University of New York).
The sample size required in Importance Sampling
S. Chatterjee
I will talk about a recent result, obtained in a joint work with Persi Diaconis, about the sample size required for importance sampling. If an i.i.d. sample from a probability measure P is used to estimate expectations with respect to a probability measure Q using the importance sampling technology, the result says that the required sample size is exp(K), where K is the Kullback-Leibler divergence of P from Q. If the sample size is smaller than this threshold, the importance sampling estimates may be far from the truth, while if the sample size is larger, the estimates are guaranteed to be close to the truth.
Continuous Time Importance Sampling for Jump Diffusions with Application to Maximum Likelihood Estimation
K. Łatuszyński
In the talk I will present a novel algorithm for sampling multidimensional irreducible jump diffusions that, unlike methods based on time discretisation, is unbiased. The algorithm can be used as a building block for maximum likelihood parameter estimation. The approach is illustrated by numerical examples of financial models like the Merton or double-jump model where its efficiency is compared to methods based on the standard Euler discretisation and Multilevel Monte Carlo. Joint work with Sylvain Le Corff, Paul Fearnhead, Gareth O. Roberts, and Giorgios Sermaidis.

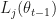

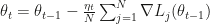


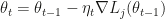
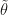


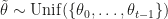




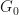 . While the abstract claims their approach works for arbitrary distributions as mixture components, really they make the assumption that the components are well approximated by a Gaussian (of course including distributions arising from sums of RVs because of the CLT). While theoretically NPMLEs might put no constraints on the base measure, practically in the paper first
. While the abstract claims their approach works for arbitrary distributions as mixture components, really they make the assumption that the components are well approximated by a Gaussian (of course including distributions arising from sums of RVs because of the CLT). While theoretically NPMLEs might put no constraints on the base measure, practically in the paper first 





 and a parametric approximation
and a parametric approximation  , we want to find
, we want to find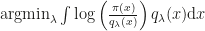

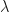 in closed form. In the original paper, the authors suggested the use of the score function as a control variate and a Rao-Blackwellization. Both where described in a way that utterly confused me – until now, because Ruiz, Titsias and Blei manage to describe the concrete application of both control variates and Rao-Blackwellization in a very transparent way. Their own contribution to variance reduction (minus some tricks they applied) is based on the fact that the optimal sampling distribution for estimating
in closed form. In the original paper, the authors suggested the use of the score function as a control variate and a Rao-Blackwellization. Both where described in a way that utterly confused me – until now, because Ruiz, Titsias and Blei manage to describe the concrete application of both control variates and Rao-Blackwellization in a very transparent way. Their own contribution to variance reduction (minus some tricks they applied) is based on the fact that the optimal sampling distribution for estimating  rather than exactly
rather than exactly  . They argue that this optimal sampling distribution is considerably heavier tailed than
. They argue that this optimal sampling distribution is considerably heavier tailed than 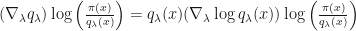 ) vanishes for the modes, making that region irrelevant for gradient estimation. The same should be true for the tails of the distribution I think. Overall very interesting work that I strongly recommend reading, if only to understand the original Blackbox VI proposal.
) vanishes for the modes, making that region irrelevant for gradient estimation. The same should be true for the tails of the distribution I think. Overall very interesting work that I strongly recommend reading, if only to understand the original Blackbox VI proposal.