
Category Archives: Monte Carlo

Nonparametric maximum likelihood inference for mixture models via convex optimization
This arXival by Feng and Dicker deals with the problem of fitting multivariate mixture estimates with maximum likelihood. One of the advantages put forward being that nonparametric maximum likelihood estimators (NPMLEs) put virtually no constraints on the base measure 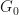
The main result of the paper is in Proposition 1, which basically says that the finite grid constraint indeed makes the problem convex. After that the paper directly continues with empirical evaluation. I think the method proposed is not all that general. While the elliptical unimodal (gaussian approximation) assumption would not be that problematic, the claimed theoretical flexibility of NPMLE is not really bearing fruit in this approach, as the finite grid constraint is very strong and gets rid of most flexibility left after the gaussian assumption. For instance, the gaussian location model fitted is merely a very constrained KDE without even allowing the ability of general gaussian mixture models of fitting the covariance matrix of individual components. While a finite grid support for location and covariance matrix is possible, to be practical the grid would have to be extremely dense in order gain flexibility in the fit. While it is correct that the optimization problem is becoming convex, this is bought for the price of a rigid model. However, Ewan Cameron assured me that the model is very useful for astrostatistics, and I realized that it might be so in other contexts, e.g. adaptive Monte Carlo techniques.
A minor comment regarding the allegation in the paper that nonparametric models lack interpretability: while this is certainly true for the model proposed in the paper and mainstream bayesian nonparametric models, this is not a given. One notable interpretable class of models are Mixture models with a prior on the number of components by Miller and Harrison (2015).
Rodin museum


Lifted Convex Quadratic Programming
This arXival by Mladenov, Kleinhans and Kersting considers taking advantage of symmetry structure in quadratic programming problems in order to speed up solvers/optimizers. The basic idea is to check which of the model parameters are indistinguishable because of symmetries in the model and assign all parameters in a group the same parameter in all steps of optimization – yielding a partition of the parameter space. Of course, this will reduce the effective dimensionality of the problem and might thus be considered a method of uncovering the lower-dimensional manifold that contains at least one optimum/solution.
The core contributions of the paper are
1) to provide the conditions under which a partition is a lifting partition, i.e. a partition such that setting all the variables in a group to the same value still includes a solution of the quadratic program
2) provide conditions under which the quadratic part of the program is fractionally symmetric , i.e. can be factorized
Furthermore, the paper touches on the fact that some kernelized learning algorithms can benefit from lifted solvers and an approximate lifting procedures when no strict lifting partition exists.
It is rather hard to read for somebody not an expert in lifted inference. While all formal criteria for presentation are fulfilled, more intuition for the subject matter could be given. The contributions of the paper are hard to grasp and more on the theoretical side (lifting partitions for convex programs can be “computed via packages such as Saucy”). While deepening the theoretical understanding a bit, it is unclear wether this paper will have a strong effect on the development of the theory of lifted inference. Even the authors seem to think that it will not have strong practical implications.
In general I wonder wether lifted inference really isn’t just an automatic way of finding simpler, equivalent models, rather than an inference technique per se.

MCqMC 2016
Yesterday, the MCqMC 2016 conference started, which I am unfortunately not attending – the program looks very interesting! Tomorrow, Nicolas Chopin will chair the session on importance sampling that I organized.
Advances in Importance Sampling
Wednesday August 17th 10:25–11:55, Berg B
Recently, there has been renewed interest in Importance Sampling, with results that go far beyond the state of the art of the early nineties when research focus shifted to MCMC. These results include theoretical advances in the analysis of convergence conditions and convergence assessment on one side. On the other, an overarching Multiple Importance Sampling framework has been proposed as well as IS based on piecewise deterministic processes, which allows, amongst other things, data subsampling and incorporating gradient information.
Generalized Multiple Importance Sampling
V. Elvira
Importance sampling methods are broadly used to approximate posterior distributions or some of their moments. In its standard approach, samples are drawn from a single proposal distribution and weighted properly. However, since the performance depends on the mismatch between the targeted and the proposal distributions, several proposal densities are often employed for the generation of samples. Under this Multiple Importance Sampling (MIS) scenario, many works have addressed the selection or adaptation of the proposal distributions, interpreting the sampling and the weighting steps in different ways. In this paper, we establish a novel general framework for sampling and weighting procedures when more than one proposal is available. The most relevant MIS schemes in the literature are encompassed within the new framework, and, moreover novel valid schemes appear naturally. All the MIS schemes are compared and ranked in terms of the variance of the associated estimators. Finally, we provide illustrative examples which reveal that, even with a good choice of the proposal densities, a careful interpretation of the sampling and weighting procedures can make a significant difference in the performance of the method. Joint work with L. Martino (University of Valencia), D. Luengo (Universidad Politecnica de Madrid) and M. F. Bugallo (Stony Brook University of New York).
The sample size required in Importance Sampling
S. Chatterjee
I will talk about a recent result, obtained in a joint work with Persi Diaconis, about the sample size required for importance sampling. If an i.i.d. sample from a probability measure P is used to estimate expectations with respect to a probability measure Q using the importance sampling technology, the result says that the required sample size is exp(K), where K is the Kullback-Leibler divergence of P from Q. If the sample size is smaller than this threshold, the importance sampling estimates may be far from the truth, while if the sample size is larger, the estimates are guaranteed to be close to the truth.
Continuous Time Importance Sampling for Jump Diffusions with Application to Maximum Likelihood Estimation
K. Łatuszyński
In the talk I will present a novel algorithm for sampling multidimensional irreducible jump diffusions that, unlike methods based on time discretisation, is unbiased. The algorithm can be used as a building block for maximum likelihood parameter estimation. The approach is illustrated by numerical examples of financial models like the Merton or double-jump model where its efficiency is compared to methods based on the standard Euler discretisation and Multilevel Monte Carlo. Joint work with Sylvain Le Corff, Paul Fearnhead, Gareth O. Roberts, and Giorgios Sermaidis.

Overdispersed Black-Box Variational Inference
This UAI paper by Ruiz, Titsias and Blei presents important insights for the idea of a black box procedure for VI (which I discussed here). The setup of BBVI is the following: given a target/posterior 

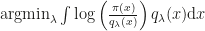
which can be achieved for any
with Monte Carlo Samples and stochastic gradient descent. This works if we can easily sample from 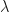



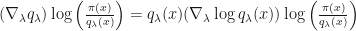

A Variational Analysis of Stochastic Gradient Algorithms
This arXival by Mandt, Hoffman and Blei from February takes a look at what they call SGD with constant learning rate or constant SGD. Which is not really Stochastic Gradient Descent anymore, but rather a sampling algorithm, as we should bounce around the mode of the posterior rather than converging to it. Consequently they interpret constant SGD as a stochastic process in discrete time with some stationary distribution. They go on to analyse it under the assumption that the stationary distribution is Gaussian (Assumption 1 and 4). Something that springs to my mind here is the following: even if we accept that the stationary distribution of the process might be Gaussian (intuitively, not rigorously), what guarantees that the stationary distribution is the posterior? Even if the posterior is also gaussian, it could have a different (co)variance. I think a few more words about this question might be good. In particular, without adding artificial noise, is it guaranteed that every point in the posteriors domain can be reached with non-zero probability? And can be reached an infinite number of times if we collect infinite samples? If not, the constant SGD process is transient and does not enjoy good stability properties.
Another delicate point hides in Assumption 1: As our stochastic gradient is the sum of independent RVs, the CLT is invoked to assume that the gradient noise is Gaussian. But the CLT might not yet take effect if the number of data points in our subsample is small, which is the very thing one would like in order to have advantages in computation time. This of course is yet another instance of the dilemma common to all scalable sampling techniques, and at this stage of research this is not a show stopper.
Now assuming that constant SGD is not transient and it has a stationary distribution that is the posterior and that the posterior or its dominant mode is approximately Gaussian, we can of course try to optimize the parameters of constant SGD to make the sample it produces as close a possible to a posterior sample. Which the authors conveniently do using an Ornstein-Uhlenbeck approximation, which has a Gaussian stationary distribution. Their approach is to minimize KL-Divergence between the OU approximation and the posterior, and derive optimal parameter settings for constant SGD in closed form. The most interesting part of the theoretical results section probably is the one on optimal preconditioning in Stochastic Gradient Fisher Scoring, as that sampler adds artificial noise. Which might solve some of the transience questions.
The presentation would gain a lot by renaming “constant SGD” for what it is – a sampling algorithm. The terminology and notation in general are sometimes a bit confusing, but nothing a revision can’t fix. In general, the paper presents an interesting approach to deriving optimal parameters for a class of algorithms that is notoriously hard to tune. This is particularly relevant because the constant step size could improve mixing considerably over Welling & Tehs SGLD. What would be interesting to see is wether the results could be generalized to the case where the posterior is not Gaussian. For practical reasons, because stochastic VB/EP works quite well in the gaussian case. For theoretical reasons, because EP now even comes with some guarantees (haven’t read that paper admittedly). Maybe a path would be to take a look at the Gaussian approximation to a multimodal posterior spanning all modes, and minimizing KL-Divergence between that and the OU process. Or maybe one can proof that constant SGD (with artificial noise?) has some fixed stationary distribution to which stochastic drift term plus noise are a Markov Kernel, which might enable a pseudo-marginal correction.

Markov Chain Monte Carlo and Variational Inference: Bridging the Gap
This ICML 2015 paper by Salimans, Kingma and Welling tries to explore ‘a new synthesis of variational inference and Monte Carlo’.
The paper looks at a potentially interesting approach, namely introducing an optimization objective for optimizing parameters of the inference algorithm and approximating some integrals appearing in the objective using Monte Carlo. I had big problems following the notation and general ideas however. The authors want to treat Monte Carlo samples as auxiliary variables and introduce a distribution 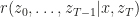

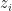

When using Monte Carlo to approximate some intractable integrals, in particular a variational lower bound, the authors claim that this gives them unbiased estimates. It is unclear to me why the estimates should be unbiased, especially if only few MC samples are collected as suggested by the paper. Completely elusive to me is the way they propose to compute gradients with respect to the lower bound.
At this point I was probably so lost that any further material in the paper had no hopes of me understanding. The proposed Hamiltonian Variational Inference is the first of these proposals I don’t really get, as is Annealed Variational Inference.
In general, I feel there is a potpourri of ideas and I am unclear how they fit together. But this of course can be a result of me not understanding what the principles of the approach are in the first place.

Variational Hamiltonian Monte Carlo via Score Matching
This is an arXival (maybe by now ICML paper?) by Zhang, Shahbaba and Zhao. It suggest fitting an emulator/surrogate 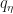
However, that seems to me like reselling the earlier paper by Heiko Strathmann and collaborators on Gradient-free Hamiltonian Monte Carlo with Efficient Kernel Exponential Families. Zhang et al use basically the same idea but fail to look at this earlier work. Their reasoning to use a neural network rather than a GP emulator (computation time) is a bit arbitrary. If you go for a less rich function class (neural network) then the computation time will go down of course – but you would get the same effect by using GPs with inducing points.
Very much lacking to my taste is reasoning for doing the tuning they do. Sometimes they tune HMC/Variational HMC to 85% acceptance, sometimes to 70% acceptance. Also, it seems they not adapting the mass matrix of HMC. If they would, I conjecture the relative efficiency of Standard HMC vs Variational HMC could change drastically. Details on how they tune SGLD is completely lacking.
Overall, I think it is not yet clear what can be learned from the work reported in the paper.
London

Currently staying in London to give talks and work with Heiko Strathmann and Marco Banterle. This is a photo from The Magazine, an old gunpowder magazine in Hyde park turned art museum.
