
This ICML 2015 paper by Salimans, Kingma and Welling tries to explore ‘a new synthesis of variational inference and Monte Carlo’.
The paper looks at a potentially interesting approach, namely introducing an optimization objective for optimizing parameters of the inference algorithm and approximating some integrals appearing in the objective using Monte Carlo. I had big problems following the notation and general ideas however. The authors want to treat Monte Carlo samples as auxiliary variables and introduce a distribution 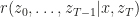

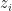

When using Monte Carlo to approximate some intractable integrals, in particular a variational lower bound, the authors claim that this gives them unbiased estimates. It is unclear to me why the estimates should be unbiased, especially if only few MC samples are collected as suggested by the paper. Completely elusive to me is the way they propose to compute gradients with respect to the lower bound.
At this point I was probably so lost that any further material in the paper had no hopes of me understanding. The proposed Hamiltonian Variational Inference is the first of these proposals I don’t really get, as is Annealed Variational Inference.
In general, I feel there is a potpourri of ideas and I am unclear how they fit together. But this of course can be a result of me not understanding what the principles of the approach are in the first place.

My way of looking at the idea is from an extended space approach. What you ideally would want to optimize is KL[q || p] where q is the marginal for the last sample q(z_T). However, since we can not evaluate this we add the intermediate auxiliary variables z_0,…,z_T-1 and consider q(z_0,…,z_T) which we can evaluate*. However, now you need to extend the distribution to approximate p accordingly without changing the marginal p(z_T). This we can easily do by introducing the extended space distribution p(z_T)r(z_0,…,z_T-1 | z_T).
Given this we can compute unbiased MC estimates of the gradient of KL[q(z_0,…,z_T) || p(z_T) r(z_0, …, z_T-1 | z_T] by rewriting it as an expectation wrt q and the functional is log(pr) gradients of log(q) both of which we can evaluate pointwise.
LikeLike
Frankly, I think your explanation is more transparent than the one in the paper.
So the gain is what? Gradients for optimizing q?
Do we still estimate integrals with MC or rather with VI? Or both?
LikeLike
Basically yes, gradients for optimizing free parameters of q. In the HMC case we can do gradient steps to optimize the mass matrix, initial distribution, etc. Note that we can not actually use the accept-reject step because that would mean again that we couldn’t evaluate q.
Integrals with respect to the posterior are then approximated using samples from q(z_T). These samples we get by just sampling all z’s from q(z_0,…,z_T), and then keep the last one.
LikeLike
And those samples are used uncorrected as far as I can see? In which case it inherits the no-guarantees problem of VI?
In any case thanks, your comments are clearing this up quite a bit for me.
LikeLike
Yep, still a variational approximation that you can’t quantify how close to the true distribution you are.
Of course you could freeze the optimized settings and start running it as a standard MCMC with an accept-reject step. This would of course give convergence results. But I guess there are then no guarantees that the parameters (mass matrix etc.) are any good since you are using them in a different context from how you optimized them.
LikeLike